-- NULL 값이 없는 상태. 문자열의 길이가 0이면 오라클은 NULL
-- IS 는 NULL인지를 확인하는 유일한 방법
-- 컬럼 IS [ NOT ] NULL
-- CASE END : 조건에 따른 결과 반환
-- DECO`DE 함수 : 검색값과 비교하여 같으면 해당 결과 반환. 하지만 CASE ~ END보다 느리다.
-- DISTINCT : 선택 행 중에서 중복적인 행은 한번만 출력
-- 집합
-- UNION
-- UNION ALL
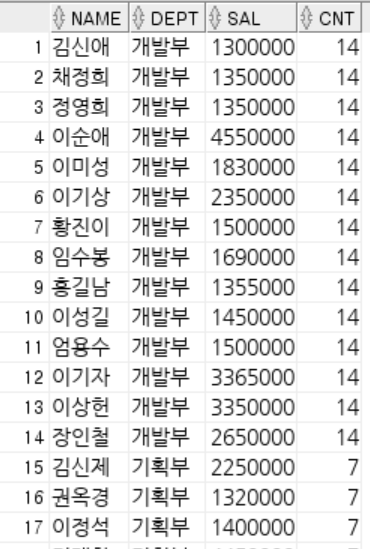
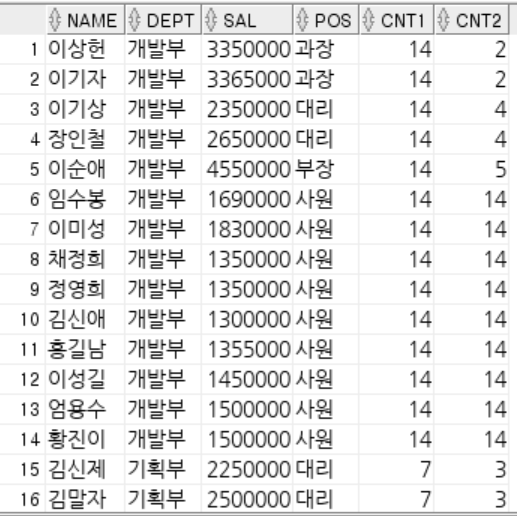
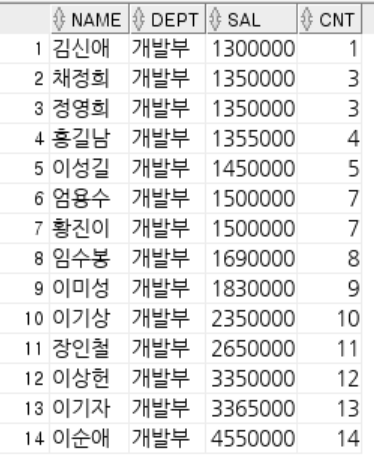
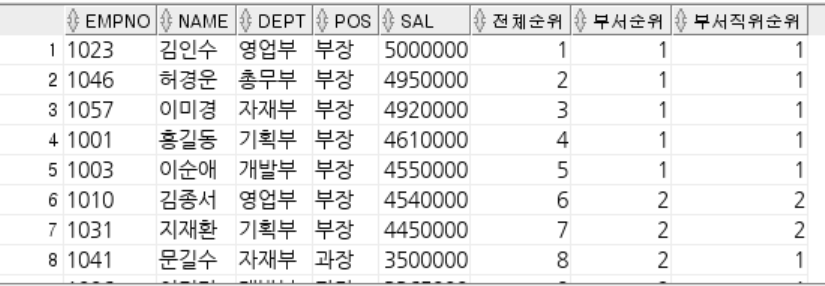
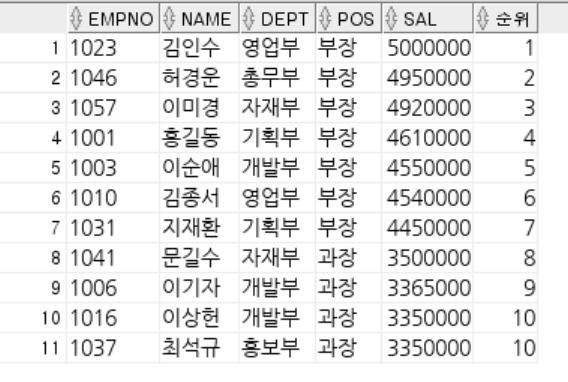
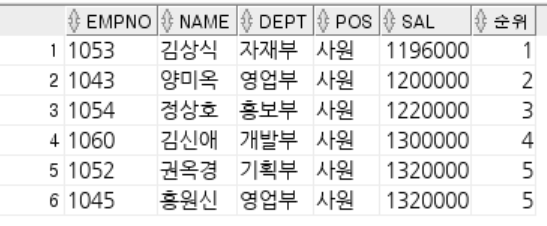
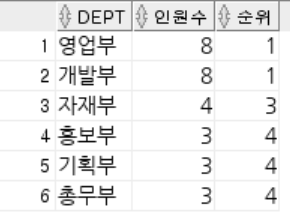
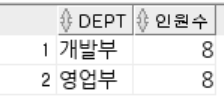
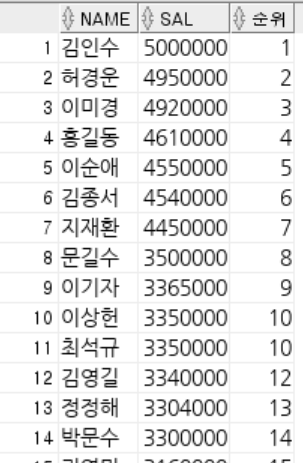
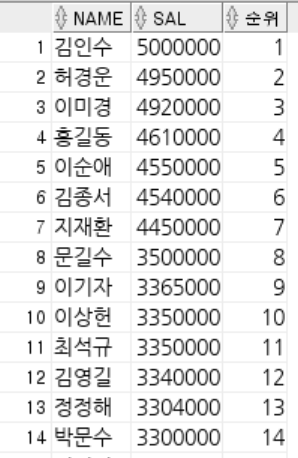
-- ROWNUM : 쿼리 결과로 나오는 각각의 행들에 대한 순서 값.
-- 1부터 시작 작거나 같다로만 사용 가능
-- LENGTH(char) : 문자열의 길이 반환(문자 개수)
SELECT LENGTH('대한민국') FROM dual;
-- 문자의 개수 반환 : 4
SELECT LENGTHB('대한민국')FROM dual;
-- 문자열의 바이트수 반환. 한글은 3byte (UTF-8)
-- REPLACE(char , search_string [, replacement_string]) : 특정 문자열을 다른 문자열로 치환
SELECT REPLACE('seoul korea', 'seoul', 'busan') FROM dual;
-- seoul을 busan으로 치환하라는 의미
SELECT REPLACE('12345123458525', '5') FROM dual;
-- 인자를 두 개만 주면 두 번째에 해당하는 문자를 문자열에서 제거 (5 제거)
SELECT name, REPLACE(dept, '부', '팀') dept FROM emp;
-- 부를 팀으로 변경. 중간에 부가 있어도 변경 : '__부' 말고 '부_부' 뭐 이런 것에서 부가 다 팀으로 바뀜
SELECT name, SUBSTR(dept, 1, 2) || '팀' dept FROM emp;
-- 부서의 이름이 4자 이상이면 문제 발생.
SELECT name, SUBSTR(dept, 1, LENGTH(dept)-1) || '팀' dept FROM emp;
-- 가장 마지막에 있는 글자를 팀으로 바꿈 : 제일 문제발생의 여지가 없다
-- CONCAT(char1, char2) : 문자열 결합
SELECT CONCAT('대한', '민국') FROM dual;
SELECT '대한'||'민국' FROM dual;
-- LPAD(expr1, n [, expr2]) 남는 왼쪽 공간에 특정 문자로 채움
-- RPAD(expr1, n [, expr2]) 남는 오른쪽 공간에 특정 문자로 채움
SELECT LPAD('korea', 12, '*') FROM dual;
SELECT RPAD('korea', 12, '*') FROM dual;
SELECT LPAD('korea', 3, '*') FROM dual;
SELECT LPAD('korea', 0, '*') FROM dual;
-- 0은 NULL
SELECT LPAD('대한', 6, '*') FROM dual;
-- 한글은 2칸으로 처리. **대한 으로 출력.
-- emp테이블 : name, rrn(성별 다음부터는 *로 출력)
SELECT name, RPAD( SUBSTR(rrn, 1, 8 ), 14, '*')
FROM emp;
-- emp테이블 : name, tel(전화번호 마지막 3자리는 *로 출력)
SELECT name, RPAD( SUBSTR(tel, 1, length(tel) -3), length(tel), '*')
FROM emp;
-- emp 테이블 : name, sal, 그래프 ( sal 10만원당 *하나씩 출력)
SELECT name, sal, RPAD ( '*', TRUNC(sal/100000), '*') 그래프
FROM emp;
-- scott 계정 emp 테이블
-- deptno 가 10인 사원의 이름(ename)과 이름(ename)을 총 9자리로 출력하되
-- 오른쪽 빈자리는 해당 자릿수로 출력
SELECT * FROM emp;
SELECT RPAD( ename, 9, (SUBSTR('123456789', LENGTH(ename)+1) ) )
FROM emp
WHERE deptno = 10;
-- LTRIM(char [, set])
-- RTRIM(char [, set])
-- TRIM([[LEADING | TRAILING | BOTH] trim_character FROM] trim_score)
-- 공백 또는 특정 문자열 제거
SELECT ':' || LTRIM(' 우리 나라 ') || ':' FROM dual;
SELECT ':' || RTRIM(' 우리 나라 ') || ':' FROM dual;
SELECT ':' || TRIM(' 우리 나라 ') || ':' FROM dual;
SELECT LTRIM('AABBBBCDAC', 'BA') FROM dual;
SELECT RTRIM('대한우리나라대한', '대한') FROM dual;
SELECT TRIM('A' FROM 'AABBACCCAA') FROM dual;
SELECT name, RTRIM(dept, '부') || '팀' dept FROM emp;
-- TRANSTALE(expr, from_string, to_string) : 치환
SELECT TRANSLATE('ababbcca', 'c', 'd') FROM dual;
SELECT TRANSLATE('2KAB35CC',
'0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ', -- (1)
'9999999999XXXXXXXXXXXXXXXXXXXXXXXXXX') FROM dual; -- (2)
-- (1) 에 해당되는 문자를 (2)로 치환한다.
-- 즉 0도 9, 1도 9, 2도 9 ...
-- A 도 X, B도 X, C도 X ...
SELECT TRANSLATE('2KAB35CC',
'0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ',
'0123456789') FROM dual;
-- 영문자는 제거
-- 날짜 + 숫자 : 숫자 만큼의 일 수를 날짜에 더함.
-- 날짜 - 숫자 : 숫자 만큼의 일수를 날짜에서 뺌
-- 날짜 + 숫자/24 : 숫자 만큼의 시간을 날짜에 더함
-- 날짜1 - 날짜2 : 날자 1에서 날짜 2를 빼면 두 날짜 사이의 일수가 나온다.
SELECT SYSDATE, CURRENT_DATE FROM dual;
SELECT SYSDATE - 1 FROM dual;
SELECT TO_CHAR(SYSDATE - 1, 'YYYY-MM-DD HH24:MI:SS') FROM dual;
SELECT SYSDATE - 1/24 FROM dual;
SELECT TO_CHAR(SYSDATE - 1/24, 'YYYY-MM-DD HH24:MI:SS')
FROM dual; -- 1시간 빼기
SELECT SYSDATE - 1/24/60 FROM dual;
SELECT TO_CHAR(SYSDATE - 1/24/60, 'YYYY-MM-DD HH24:MI:SS')
FROM dual; -- 1분 빼기
-- 문자열을 날짜로 변환
SELECT TO_DATE('2000-10-10', 'YYYY-MM-DD') FROM dual;
-- 오늘까지 살아온 날 수
SELECT TRUNC(SYSDATE - TO_DATE('1996-09-19', 'YYYY-MM-DD') ) FROM dual;
-- 홍길동이 2021년 7월 10일에 여자친구를 만났다. 100일 후는 ?
SELECT TO_DATE('2021-07-10', 'YYYY-MM-DD') + 100 FROM dual;
-- 2021-12-25일까지의 디데이
SELECT TRUNC(TO_DATE('2021-12-25', 'YYYY-MM-DD') - SYSDATE) FROM dual;
-- emp 테이블에서 입사한지 100일이 되지 않은 사원 출력 : name, hireDate
SELECT name, hireDate, TRUNC(SYSDATE - hireDate) 근무일수
FROM emp
WHERE (SYSDATE - hireDate) < 100;
-- 1년 후 오늘
SELECT SYSDATE + (INTERVAL '1' YEAR) FROM dual;
-- 1년 전 오늘
SELECT SYSDATE - (INTERVAL '1' YEAR) FROM dual;
-- 1달 전
SELECT SYSDATE + (INTERVAL '1' MONTH) FROM dual;
-- 1달 후
SELECT SYSDATE - (INTERVAL '1' MONTH) FROM dual;
-- 1일 전
SELECT SYSDATE + (INTERVAL '1' DAY) FROM dual;
-- 1일 후
SELECT SYSDATE - (INTERVAL '1' DAY) FROM dual;
-- 1시간 전
SELECT SYSDATE + (INTERVAL '1' HOUR) FROM dual;
-- 1시간 후
SELECT SYSDATE - (INTERVAL '1' HOUR) FROM dual;
-- 1분 후
SELECT SYSDATE + (INTERVAL '1' MINUTE) FROM dual;
-- 1초 후
SELECT SYSDATE - (INTERVAL '1' SECOND) FROM dual;
-- 2시간 30분 전
SELECT SYSDATE - ( INTERVAL '02:30' HOUR TO MINUTE) FROM dual;
SELECT TO_CHAR( SYSDATE - ( INTERVAL '02:30' HOUR TO MINUTE), 'YYYY-MM-DD HH24:MI:SS')
FROM dual;
-- 근속년수가 1년 미만인 사람 출력 : name ,hireDate
SELECT name, hireDate
FROM emp
WHERE (hireDate + (INTERVAL '1' YEAR)) > SYSDATE ;
-- 날짜 함수 종류
-- SYSDATE : 현재 시스템 날짜 및 시간(YYYY-MM-DD HH24:MI:SS). ms는 출력 안됨
-- CURRENT_DATE : 현재 시스템 날짜를 그레고리력 값으로 반환
-- SYSTIMESTAMP : ms 까지 출력
SELECT SYSDATE, CURRENT_DATE FROM dual;
SELECT SYSTIMESTAMP FROM dual;
-- 근무일수
SELECT name, TRUNC(SYSDATE - hireDate) 근무일수 FROM emp;
SELECT name, (SYSDATE - hireDate) 근무일수 FROM emp;
-- EXTRACT 지정된 날짜 시간 필드 값을 추출
SELECT EXTRACT( YEAR FROM SYSDATE ) FROM dual;
SELECT EXTRACT( MONTH FROM SYSDATE ) FROM dual;
SELECT EXTRACT( DAY FROM SYSDATE ) FROM dual;
-- name, hireDate, 입사년도
SELECT name, hireDate, EXTRACT( YEAR FROM hireDate) 입사년도
FROM emp;
-- name, hireDate : 2010년 이후에 입사한 사람
SELECT name, hireDate, EXTRACT( YEAR FROM hireDate) 입사년도
FROM emp
WHERE EXTRACT( YEAR FROM hireDate) > = 2010;
-- MONTHS_BETWEEN(date1, date2) : 날짜 사이의 월 수
-- 문자열을 날짜로 변환
SELECT TO_DATE('2000-10-10', 'YYYY-MM-DD') FROM dual; -- 되도록 이렇게 쓰는 것을 권장
SELECT TO_DATE('2000-10-10') FROM dual; -- 가능할 수도 있고 불가능할 수도 있음.
SELECT MONTHS_BETWEEN(
TO_DATE('2021-08-05', 'YYYY-MM-DD'), TO_DATE('2021-07-02', 'YYYY-MM-DD') )
FROM dual;
-- name, hireDate, 근무년수
SELECT name, hireDate,
TRUNC(MONTHS_BETWEEN(SYSDATE, hireDate) / 12 ) 근무년수
FROM emp;
-- 날짜 포맷
SELECT TO_DATE('80/05/05', 'YY-MM-DD') FROM dual; -- YY는 현재 시스템 날짜 기준
SELECT TO_CHAR(TO_DATE('80/05/05', 'YY-MM-DD'), 'YYYY-MM-DD') FROM dual;
SELECT TO_DATE('80/05/05', 'RR-MM-DD') FROM dual;
SELECT TO_CHAR(TO_DATE('80/05/05', 'RR-MM-DD'), 'YYYY-MM-DD') FROM dual;
SELECT TO_DATE('48/05/05', 'RR-MM-DD') FROM dual;
SELECT TO_CHAR(TO_DATE('48/05/05', 'RR-MM-DD'), 'YYYY-MM-DD') FROM dual;
-- 현재 세기가 0~49사이에 있으므로
-- name, rrn, 성별, 생년월일, 나이
SELECT name, rrn, DECODE( MOD(SUBSTR(rrn, 8, 1), 2), 0, '여자', '남자') 성별
FROM emp;
SELECT name, rrn, DECODE( MOD(SUBSTR(rrn, 8, 1), 2), 0, '여자', '남자') 성별,
TO_CHAR( TO_DATE(SUBSTR(rrn, 1, 6), 'RRMMDD'), 'YYYY-MM-DD') 생년월일 FROM emp; -- 년도의 RR은 문제를 발생할 수 있다.
SELECT name, rrn, DECODE( MOD(SUBSTR(rrn, 8, 1), 2), 0, '여자', '남자') 성별,
TO_CHAR( TO_DATE(SUBSTR(rrn, 1, 6), 'RRMMDD'), 'YYYY-MM-DD') 생년월일,
TRUNC( MONTHS_BETWEEN ( SYSDATE, TO_DATE( SUBSTR(rrn, 1, 6), 'RRMMDD') ) / 12 ) 나이
FROM emp; -- 년도의 RR은 문제를 발생할 수 있다.
-- 생년월일, 나이 등을 계산할 때 RR은 문제를 발생할 수 있다.
-- 2021년도에 48년을 RR로 표현하면 2048년이 되기 때문이다.
WITH tb AS(
SELECT empNo, name, rrn,
DECODE(MOD(SUBSTR(rrn, 8, 1), 2), 0, '여자', '남자') gender,
TO_DATE( -- 날짜자료형으로 바꾼다.
CASE
WHEN SUBSTR(rrn, 8, 1) IN (1, 2, 5, 6) THEN '19' -- 년도
WHEN SUBSTR(rrn, 8, 1) IN (3, 4, 7, 8) THEN '20'
ELSE '18'
END || SUBSTR(rrn, 1, 6), 'YYYYMMDD'
) birth
FROM emp
)
SELECT empNo, name, rrn, gender, TO_CHAR(birth, 'YYYY-MM-DD') birth,
TRUNC(MONTHS_BETWEEN(SYSDATE, birth) / 12 ) age
FROM tb;
-- ADD_MONTHS(date, integer) : 날짜에 개월을 더한다.
SELECT SYSDATE, ADD_MONTHS(SYSDATE, 1) 다음달 FROM dual;
SELECT SYSDATE, ADD_MONTHS(SYSDATE, -1) 이전달 FROM dual;
SELECT ADD_MONTHS( TO_DATE('20210330', 'YYYYMMDD'), 6),
ADD_MONTHS( TO_DATE('20210331', 'YYYYMMDD'), 6)
FROM dual;
-- 최근 6개월 이내 입사한 사람 : name, hireDate
SELECT name, hireDate
FROM emp
WHERE ADD_MONTHS(hireDate, 6) > SYSDATE; -- 6개월까지 포함하고 싶으면 = 을 붙임
-- LAST_DAY(date) : 월의 마지막 일자 (28, 29, 30, 31)
SELECT SYSDATE, LAST_DAY( SYSDATE ) FROM dual;
-- ROUND(date [, fmt]) : 지정된 단위로 반올림
-- YEAR : 7월 1일 기준 / MONTH : 16일 기준
SELECT ROUND( TO_DATE('2007-07-10', 'YYYY-MM-DD'), 'YEAR') FROM dual;
-- 2008-01-01
SELECT ROUND( TO_DATE('2007-06-10', 'YYYY-MM-DD'), 'YEAR') FROM dual;
-- 2007-01-01
SELECT ROUND( TO_DATE('2007-07-20', 'YYYY-MM-DD'), 'MONTH') FROM dual;
-- 2007-08-01
SELECT ROUND( TO_DATE('2007-07-10', 'YYYY-MM-DD'), 'MONTH') FROM dual;
-- 2007-07-01
-- TRUNC(date [, fmt]) : 날짜를 내림
SELECT TRUNC( TO_DATE('2007-07-10', 'YYYY-MM-DD'), 'YEAR') FROM dual;
SELECT TRUNC( TO_DATE('2007-08-10', 'YYYY-MM-DD'), 'YEAR') FROM dual;
SELECT TO_CHAR( SYSDATE, 'YYYY-MM-DD HH24:MI:SS' ) FROM dual;
-- 홍길동의 생년월일은 1995-10-15일 입니다. 생일까지 몇일 남아 있나요 ?
SELECT name, TO_CHAR( TO_DATE(SUBSTR(rrn, 1, 6), 'RRMMDD'), 'YYYYMMDD' ) 생년월일
FROM emp
WHERE name = '홍길동';
SELECT
TRUNC( TO_DATE(EXTRACT ( YEAR FROM SYSDATE) || SUBSTR('1995-10-15', 5), 'YYYY-MM-DD')
- TRUNC( SYSDATE) ) 남은일자
FROM dual;
-- emp : name, rrn, birth 생일까지 남은 일자
WITH tb AS (
SELECT name, rrn,
TO_DATE ( SUBSTR(rrn, 1, 6), 'RRMMDD' ) birth,
TO_DATE (EXTRACT( YEAR FROM SYSDATE) || SUBSTR(rrn, 3, 4), 'YYYYMMDD') sdate
FROM emp -- 올해생일로 맞춰줌
)
SELECT name, rrn, birth,
CASE
WHEN TRUNC ( SYSDATE ) <= sdate THEN TRUNC( sdate - TRUNC( SYSDATE ) )
-- sdate가 크다는 것 - 아직 생일이 지나지 않음 따라서 오늘날짜를 빼줌
ELSE TRUNC( ( sdate + (INTERVAL '1' YEAR) ) - TRUNC( SYSDATE) )
-- 올해에 이미 생일이 지났으면, sdate에 1년을 더 더해주고 오늘날짜를 뺌
END 남은일자
FROM tb;
-- NEXT_DAT(date, char) : 이름(char)으로 지정된 첫번째 요일 반환
-- char은 숫자로 지정가능(1:일, 2:월,...7)
SELECT SYSDATE, NEXT_DAY(SYSDATE, '토요일') FROM dual;
SELECT SYSDATE, NEXT_DAY(SYSDATE, '목요일') FROM dual;
SELECT SYSDATE, NEXT_DAY(SYSDATE, 7) FROM dual;
SELECT SYSDATE, NEXT_DAY(SYSDATE, 5) FROM dual;
-- 오늘, 이번주 일요일, 이번주 토요일 출력
SELECT SYSDATE, NEXT_DAY( SYSDATE-7 , 1), NEXT_DAY( SYSDATE-1, 7) FROM dual;
SELECT SYSDATE, NEXT_DAY( SYSDATE , 1)-7, NEXT_DAY( SYSDATE-1, 7) FROM dual;
-- 오늘 이후의 다가오는 토요일이 나오기 때문에, 토요일일 경우는 -1을 하지않으면 다음주 토요일이 나옴.
SELECT TO_DATE('20210808', 'YYYYMMDD'), -- 형식을 안넣으면 다른 환경에서는 (MAC, LINUX) 안됨.
NEXT_DAY(TO_DATE('20210808', 'YYYYMMDD') , 1)-7,
NEXT_DAY(TO_DATE('20210808', 'YYYYMMDD')-1, 7)
FROM dual;
-- 단일행 변환 함수
-- 암시적 형 변환 - 오라클 서버에 의해 자동 형 변환
SELECT 30 + '30' FROM dual; -- 60. 자동으로 문자열이 숫자로 변환
SELECT 30 || '30' FROM dual; -- 3030. 자동으로 숫자가 문자열로 변환
SELECT 20 || '대' FROM dual; -- 자동으로 숫자가 문자열로 변환
SELECT 30 + '3,300' FROM dual; -- 에러. , 가 있어서 숫자로 바꾸지 못함.
SELECT SYSDATE - ' 2021-08-01' FROM dual; --에러
SELECT * FROM NLS_SESSION_PARAMETERS;
-- 날짜 출력 형식 변경 (디폴트 : RR/MM/DD)
ALTER SESSION SET NLS_DATE_FORMAT = 'YYYY-MM-DD';
-- 변환 함수
-- TO_CHAR(n [, fmt[, 'nlsparam'] ] ) 숫자를 문자로 변환
SELECT TO_CHAR(12345, '999,999') FROM dual;
SELECT TO_CHAR(12345, '9,999') FROM dual
-- ##### 자리수가 부족하면 #으로 표시
SELECT TO_CHAR(12345, '0,999,999') FROM dual; -- 0, 012,345
-- 남는 자리수는 0으로 채움
SELECT TO_CHAR(12.67, '99') FROM dual; -- 13 반올림
SELECT TO_CHAR(12.34, '99') FROM dual; -- 12
SELECT TO_CHAR(12.67, '99.9') FROM dual; -- 12.7
SELECT TO_CHAR(0.03, '99.9') FROM dual; -- .0
SELECT TO_CHAR(36, '99.9') FROM dual; -- 36.0
SELECT TO_CHAR(36, '99.0') FROM dual; -- 36.0
SELECT TO_CHAR(0, '99') FROM dual; -- 0
SELECT TO_CHAR(1234, '9999MI') FROM dual; -- 1234
SELECT TO_CHAR(-1234, '9999MI') FROM dual; -- 1234-
SELECT TO_CHAR(1234, '9999PR') FROM dual; -- 1234
SELECT TO_CHAR(-1234, '9999PR') FROM dual; -- <1234>
SELECT TO_CHAR(1234.345, '9.999EEEE') FROM dual; -- 1.234E+03
SELECT TO_CHAR(300, '9999V9999') FROM dual; -- 3000000
SELECT TO_CHAR(1234, 'L9,999,999') FROM dual;
SELECT TO_CHAR(1234, '9,999,999')||'원' FROM dual; --1,234원
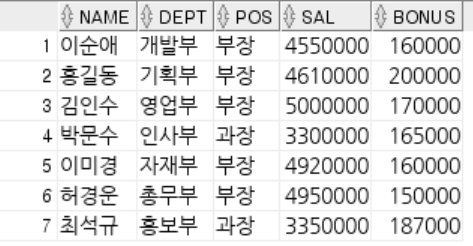
SELECT name, sal + bonus pay FROM emp;
SELECT name, TO_CHAR(sal + bonus, 'L99,999') pay FROM emp;
SELECT name, TO_CHAR(sal + bonus, 'L99,999,999') pay FROM emp;
-- TO_CHAR : 날짜를 문자열로 변환
SELECT TO_CHAR ( SYSDATE, 'YYYY-MM-DD HH24:MI:SS') 지금날짜 FROM dual;
SELECT SYSDATE, TO_CHAR(SYSDATE, 'YYYY-MM-DD DAY') FROM dual; -- DAY : 요일 출력ㄴㄴ
SELECT SYSDATE, TO_CHAR(SYSDATE, 'YYYY-MM-DD D') FROM dual; -- D : 요일을 숫자로 (1~7)
SELECT SYSDATE, TO_CHAR(SYSDATE, 'YYYY년 MM월 DD일') FROM dual; -- 에러
SELECT SYSDATE, TO_CHAR(SYSDATE, 'YYYY"년"MM"월"DD"일"') FROM dual;
-- 2000년도에 입사한 사람
SELECT name, hireDate
FROM emp
WHERE TO_CHAR(hireDate, 'YYYY') = 2000;
SELECT name,
TO_CHAR(hireDate, 'YYYY"년"MM"월"DD"일" DAY') 입사일
FROM emp;
-- 월을 영어로
SELECT SYSDATE, TO_CHAR( SYSDATE, 'MON DD DAY'),
TO_CHAR( SYSDATE, 'MON DD DAY', 'NLS_DATE_LANGUAGE = korean') ko,
TO_CHAR( SYSDATE, 'MON DD DAY', 'NLS_DATE_LANGUAGE = american') en
FROM dual;
-- DY : 요일을 간단히
SELECT SYSDATE,
TO_CHAR( SYSDATE, 'Dy MONTH DD, YYYY', 'NLS_DATE_LANGUAGE=ENGLISH') a1,
TO_CHAR( SYSDATE, 'dy month dd, YYYY', 'NLS_DATE_LANGUAGE=ENGLISH') a2,
TO_CHAR( SYSDATE, 'DY MONTH DD, YYYY', 'NLS_DATE_LANGUAGE=ENGLISH') a3
FROM dual;
-- 주
-- w : 월기준(1~5까지 나옴), 1일~7일 : 1주, 8일~14일 2주
-- ww : 년기준, 1월 1일~ 1월 7일 : 1주, ...(1~ 53주)
-- iw : 년기준. 1~52 또는 53주. 주는 월요일이 시작. 한해의 1주는 1월 4일을 포함.
SELECT TRUNC( SYSDATE) 오늘,
TO_CHAR( SYSDATE, 'd') "요일(수치)",
TO_CHAR( TRUNC( SYSDATE, 'd'), 'YYYYMMDD') "일요일",
-- TRUNC( SYSDATE, 'd') 이거는 무조건 일요일이 나옴. 주를 기준으로 내림 ( 그 주의 일요일)
TO_CHAR( SYSDATE, 'w') "월기준주차",
TO_CHAR( SYSDATE, 'ww') "년기준주차1",
TO_CHAR( SYSDATE, 'iw') "년기준주차2"
FROM dual;
-- NULL 관련 함수
-- 비교 : 컬럼 IS [NOT] NULL
-- 길이가 0인 문자열도 NULL
SELECT 10+NULL FROM dual; -- NULL
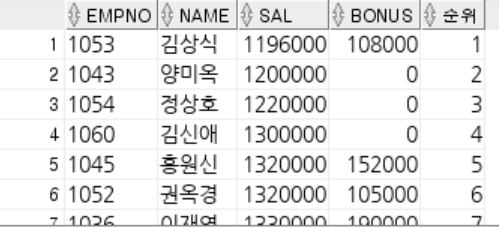
-- NVL(expr1, expr2) : expr1이 NULL이면 expr2를 반환하고 그렇지 않으면 expr1반환
SELECT name, NVL(tel, '전화없음')
FROM emp;
CREATE TABLE userEx (
empNo VARCHAR2(10) PRIMARY KEY,
name VARCHAR2(30) NOT NULL,
sal NUMBER(10) NOT NULL,
bonus NUMBER(10)
);
INSERT INTO userEx(empNo, name, sal, bonus) VALUES ('1001', '오라클', 2200000, 300000);
INSERT INTO userEx(empNo, name, sal, bonus) VALUES ('1002', '스프링', 2300000, 200000);
INSERT INTO userEx(empNo, name, sal, bonus) VALUES ('1003', '이자바', 2300000, NULL);
INSERT INTO userEx(empNo, name, sal, bonus) VALUES ('1004', '서블릿', 1900000, 200000);
INSERT INTO userEx(empNo, name, sal, bonus) VALUES ('1005', '스파크', 1700000, NULL);
COMMIT;
SELECT * FROM cols;
SELECT * FROM TAB;
SELECT * FROM userEX;
SELECT name, sal, bonus, sal+bonus pay FROM userEx; -- 문제 발생
SELECT name, sal, bonus, sal+NVL(bonus, 0) pay FROM userEx;