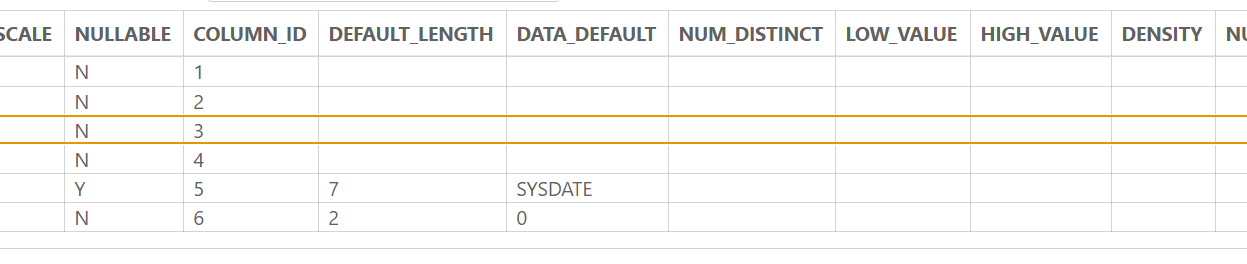
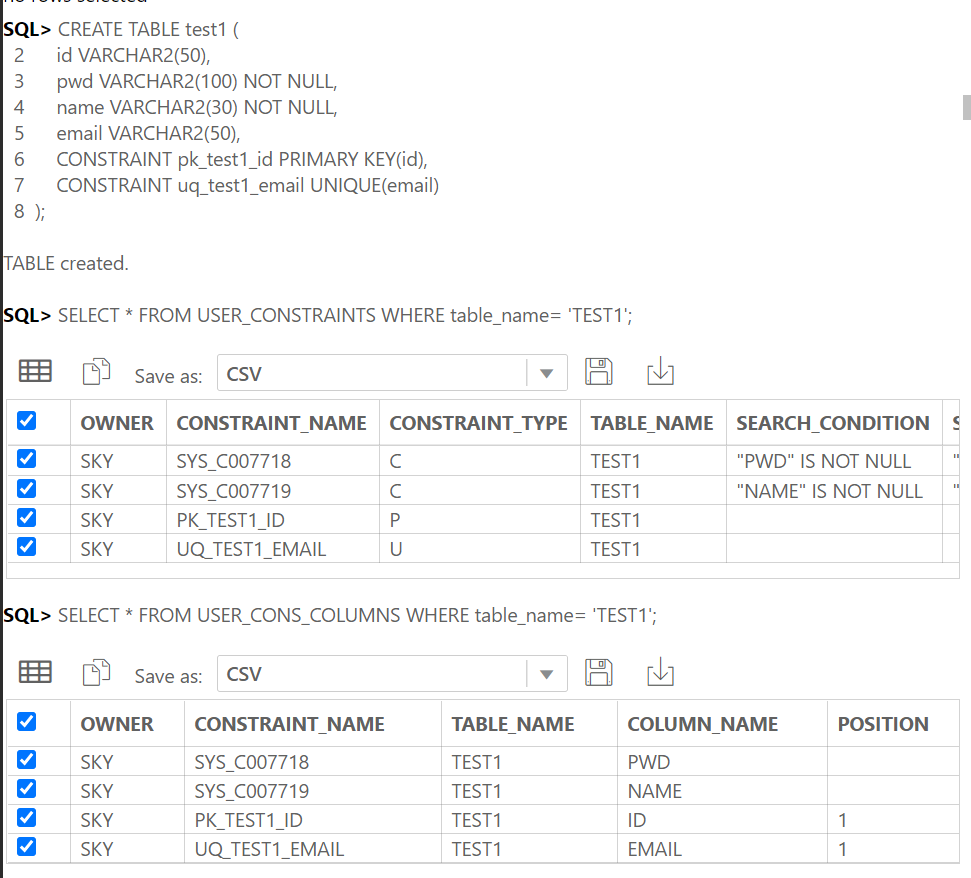
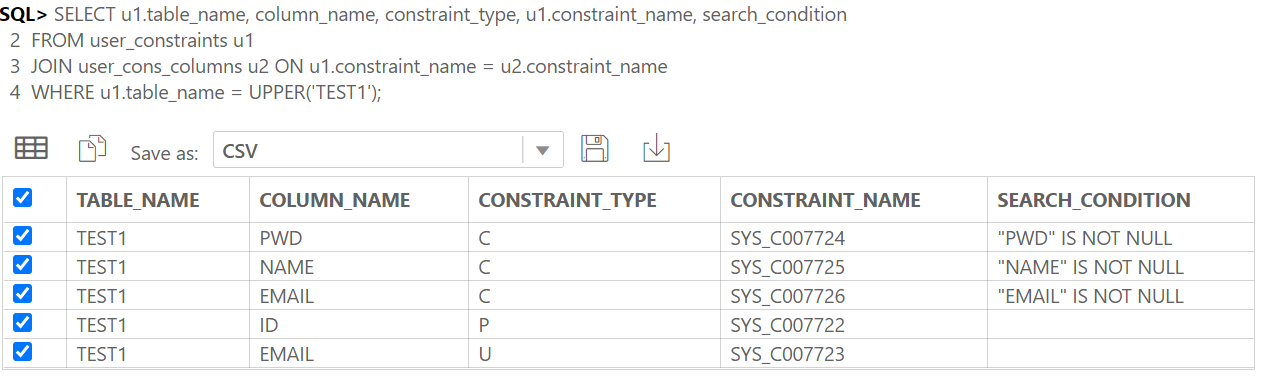
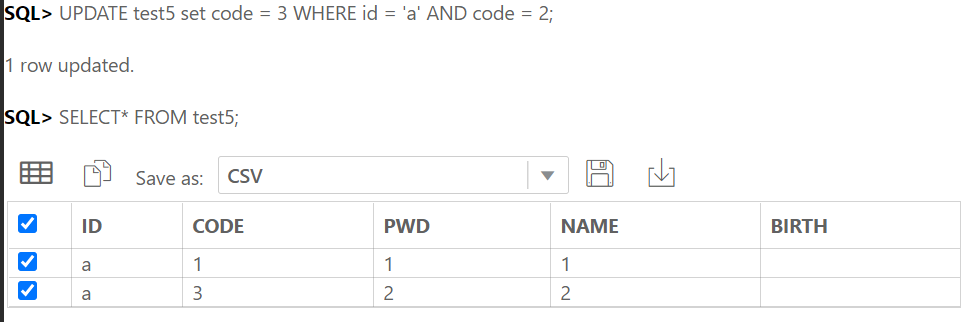
테이블 간의 관계
먼저 만들 테이블의 ERD이다.
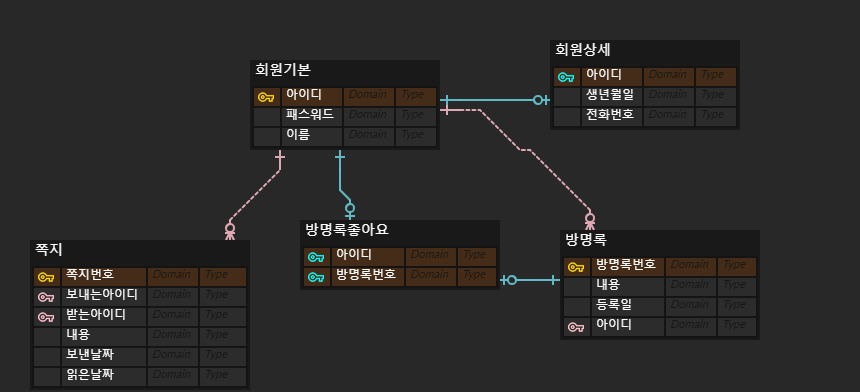
이 다이어그램은 https://www.erdcloud.com/ 에서 만들 수 있다.
식별관계에 대해 예시를 통해 먼저 알아보자.
CREATE TABLE member1 (
id VARCHAR2(30) PRIMARY KEY,
pwd VARCHAR2(100) NOT NULL,
name VARCHAR2(30) NOT NULL
);
-- 관계 -> 1:1(식별관계, 기본키이면서 참조키)
CREATE TABLE member2 (
id VARCHAR2(30),
birth DATE,
tel VARCHAR2(30),
CONSTRAINT pk_member2_id PRIMARY KEY(id),
CONSTRAINT fk_member2_id FOREIGN KEY(id)
REFERENCES member1(id)
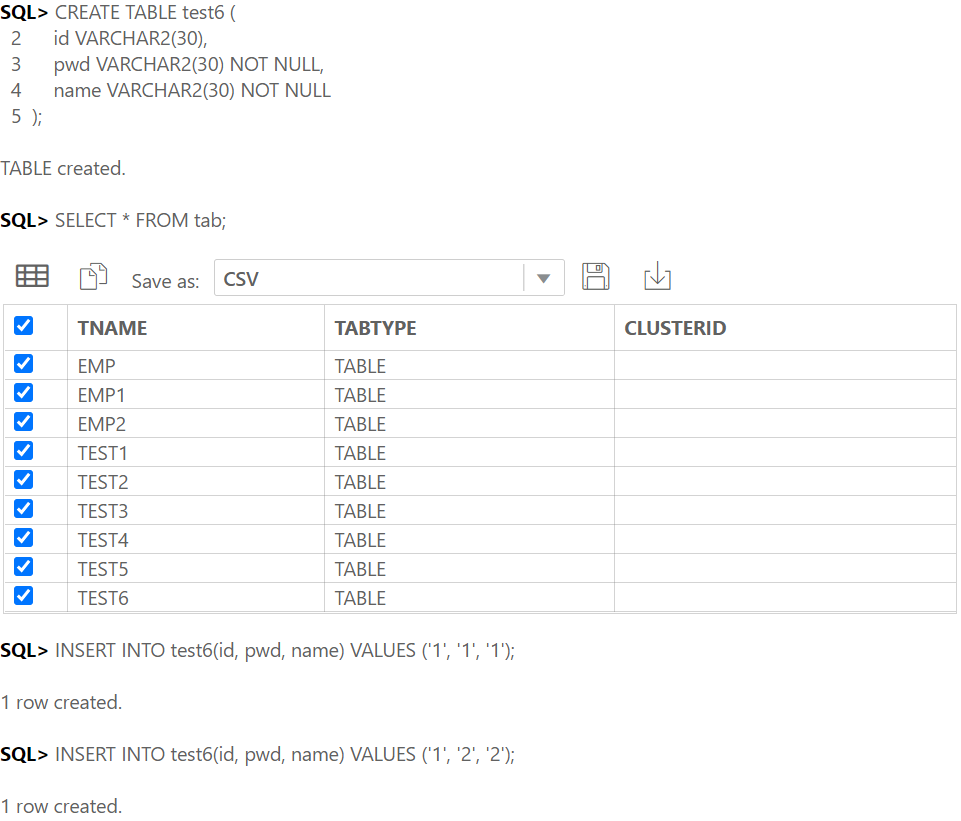
);1:1의 식별관계일 때, member1 테이블에 id 데이터가 꼭 있어야member2테이블에서는 그 id를 참조키로 하여금 birth와 tel을 식별할 수 있다. 또 member2의 기본키도 id이다.
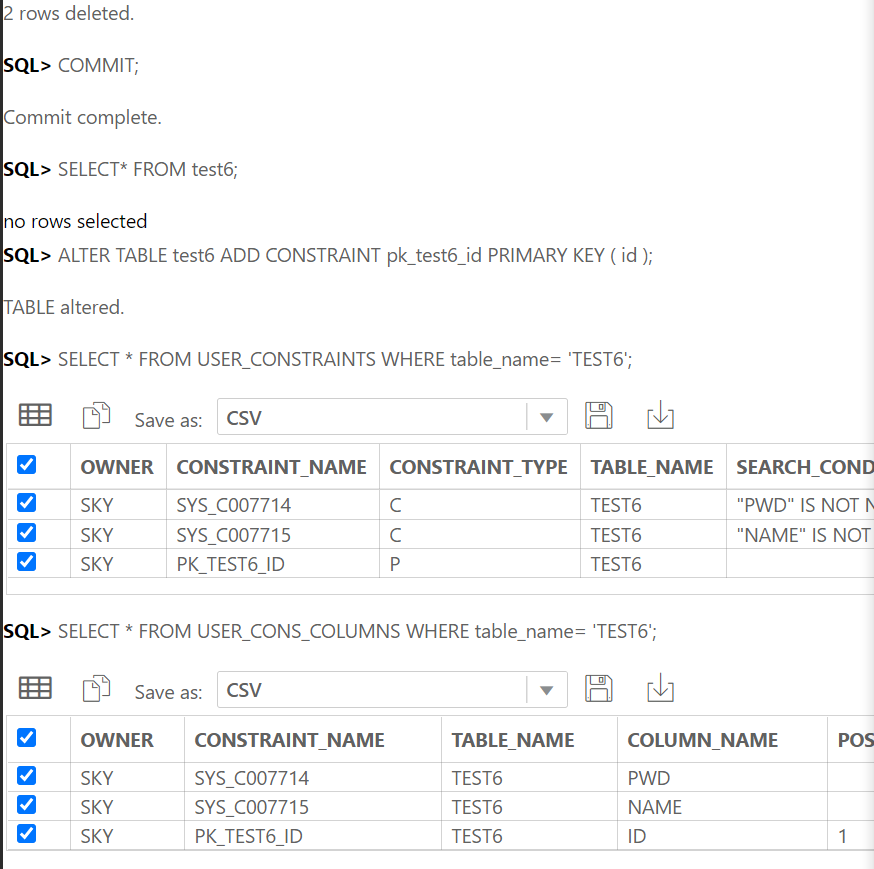
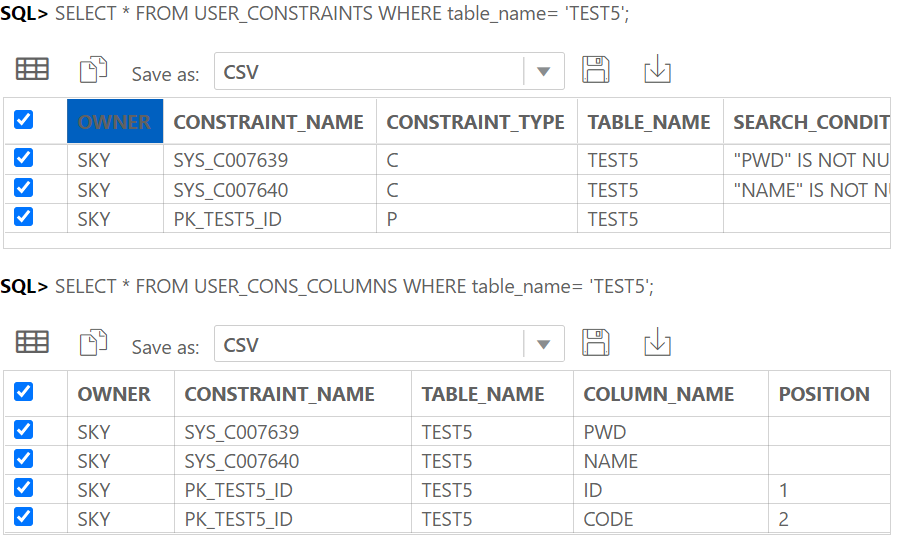
기본키이면서 참조키일 때 식별관계라고 한다.
비식별관계는 단순히 참조만 할 때 비식별관계라고한다.
예시
-- 관계 -> 1:다(비식별관계, 단순한 참조키)
CREATE TABLE guest (
num NUMBER PRIMARY KEY,
id VARCHAR2(30) NOT NULL,
content VARCHAR2(4000) NOT NULL,
reg_date DATE DEFAULT SYSDATE,
FOREIGN KEY(id)
REFERENCES member1(id)
);guest 테이블에서는 member1의 id컬럼은 단순한 참조키이다.
1:다, 식별관계
-- 두개의 컬럼을 기본키로 설정. 참조키 2개 식별관계
-- 관계 member1 : guestLikst => 1:다, guest : guestLike => 1:다
CREATE TABLE guestLike ( -- LIKE 예약어이기 때문에 단독으로 이름으로 줄 수 없음.
num NUMBER,
id VARCHAR2(30),
PRIMARY KEY(num, id),
FOREIGN KEY(num)
REFERENCES guest(num),
FOREIGN KEY(id)
REFERENCES member1(id)
);
1:다, 비식별관계
-- 동일한 컬럼을 두 번 참조 : 예 -> 쪽지 테이블
-- 1:다, 비식별
CREATE TABLE note (
num NUMBER PRIMARY KEY,
sendId VARCHAR2(30) NOT NULL,
receiveID VARCHAR2(30) NOT NULL,
content VARCHAR2(4000) NOT NULL,
FOREIGN KEY(sendId)
REFERENCES member1(id),
FOREIGN KEY(receiveId)
REFERENCES member1(id)
);
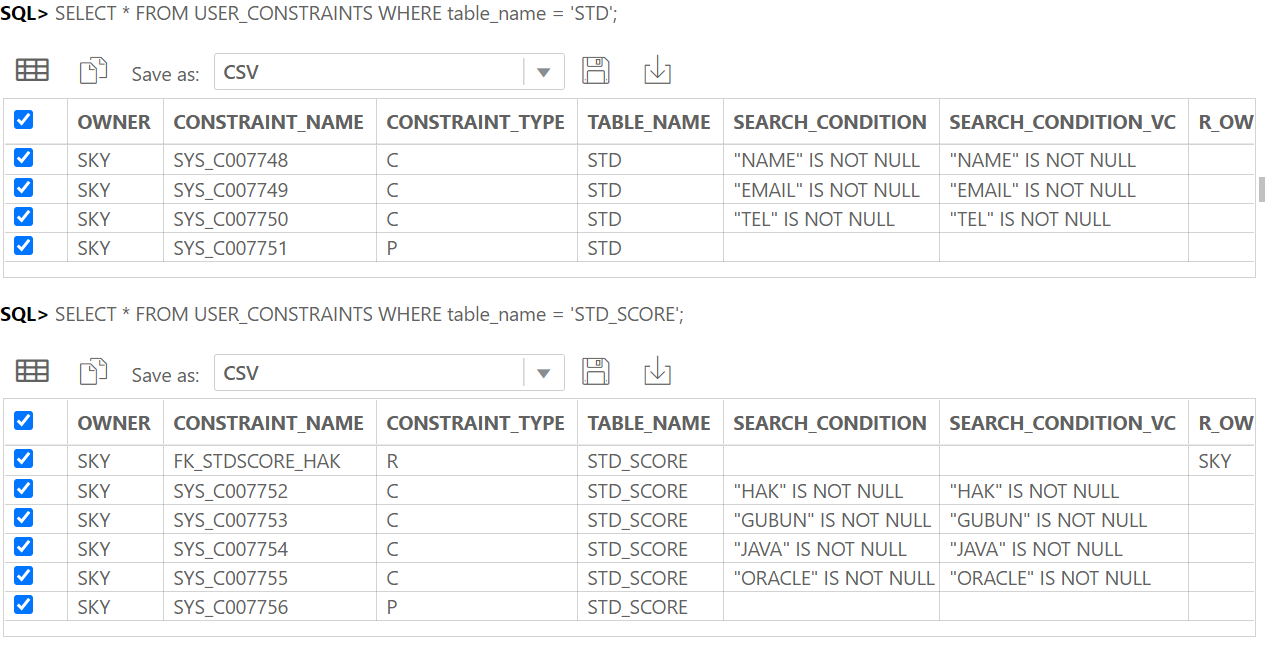
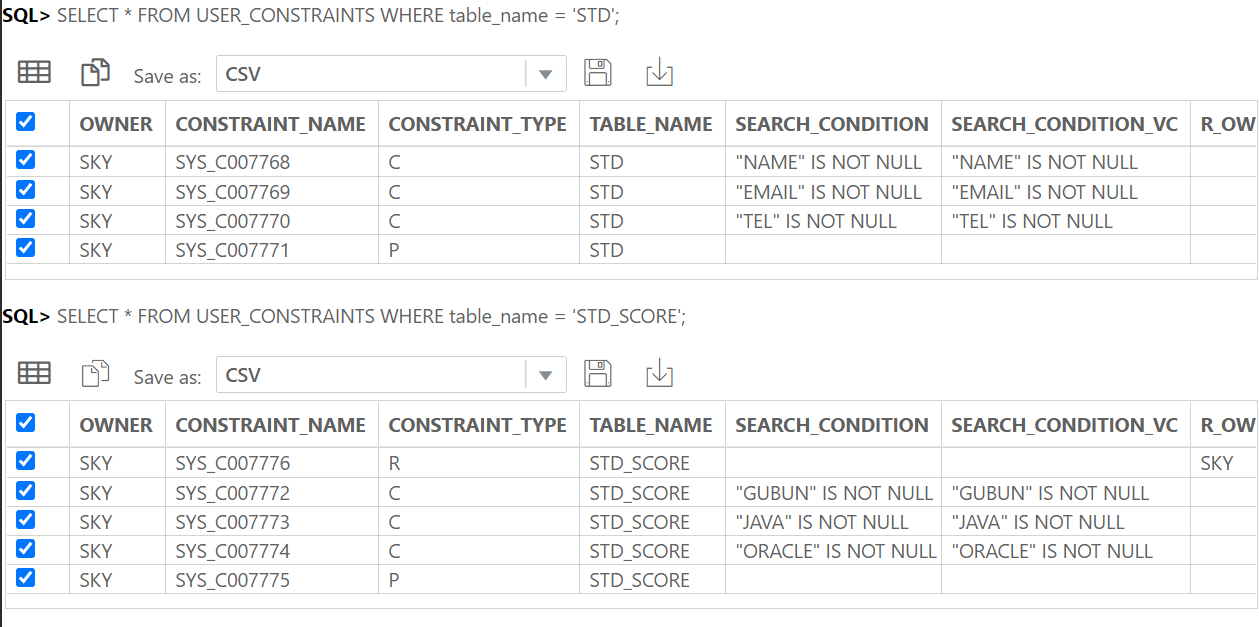
테이블을 확인할 때 알아두면 좋은 쿼리들 >
1) 부와 자 관계의 모든 테이블 출력하는 쿼리
SELECT fk.owner, fk.constraint_name,
pk.table_name parent_table, fk.table_name child_table
FROM all_constraints fk, all_constraints pk
WHERE fk.r_constraint_name = pk.constraint_name AND fk.constraint_type = 'R'
ORDER BY fk.table_name;2) 『테이블명』을 참조하는 모든 테이블 목록 출력(자식 테이블 목록 출력)
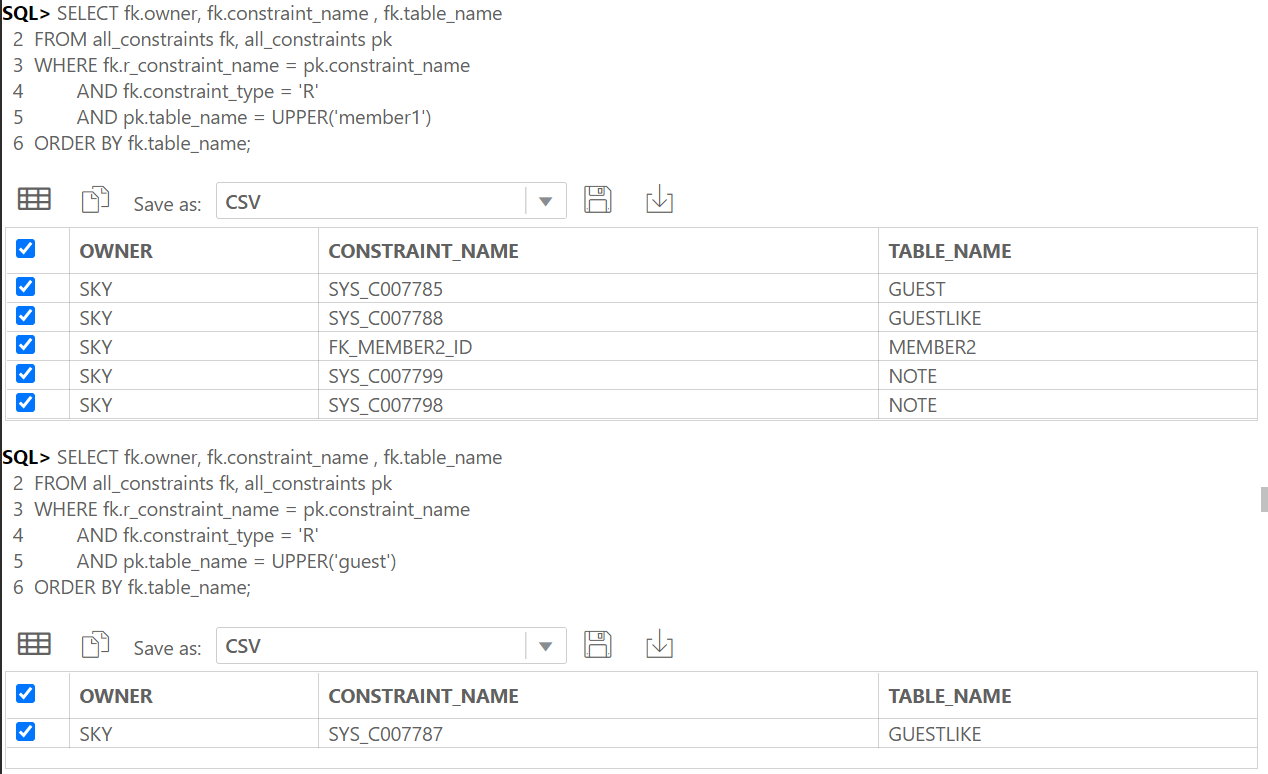
SELECT fk.owner, fk.constraint_name , fk.table_name
FROM all_constraints fk, all_constraints pk
WHERE fk.r_constraint_name = pk.constraint_name
AND fk.constraint_type = 'R'
AND pk.table_name = UPPER('테이블명')
ORDER BY fk.table_name;3) 『테이블명』이 참조하고 있는 모든 테이블 목록 출력(부모 테이블 목록 출력)
SELECT table_name FROM user_constraints
WHERE constraint_name IN (
SELECT r_constraint_name
FROM user_constraints
WHERE table_name = UPPER('테이블명') AND constraint_type = 'R'
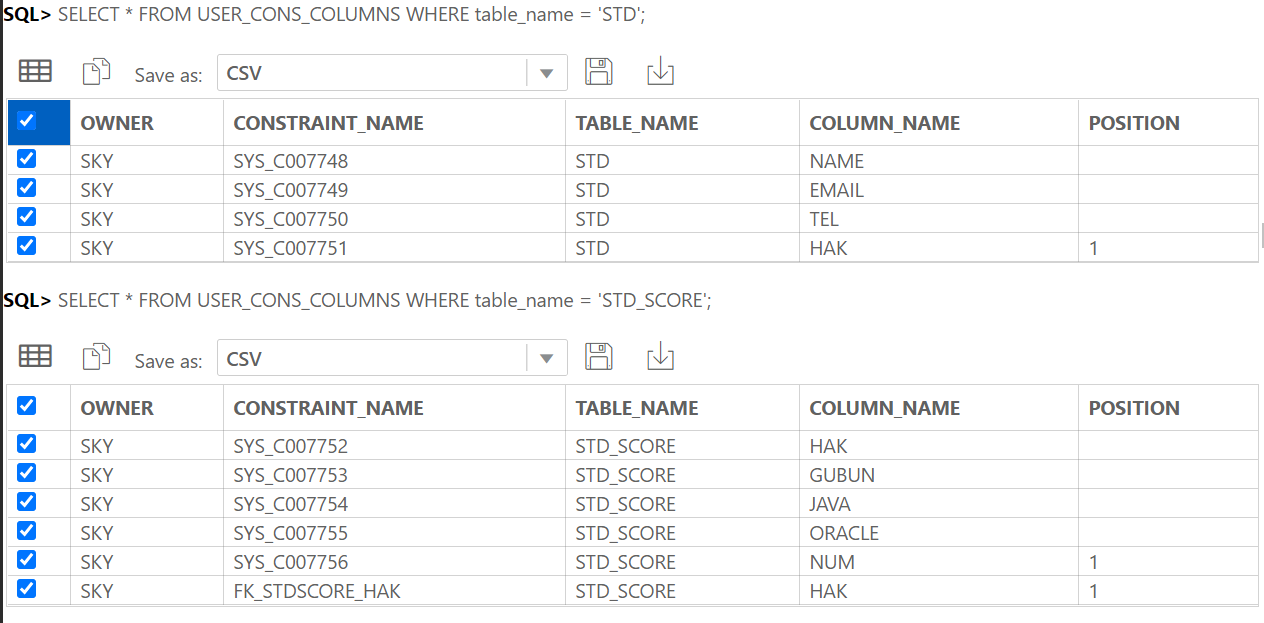
);4) 『테이블명』의 부모 테이블 목록 및 부모 컬럼 목록 출력
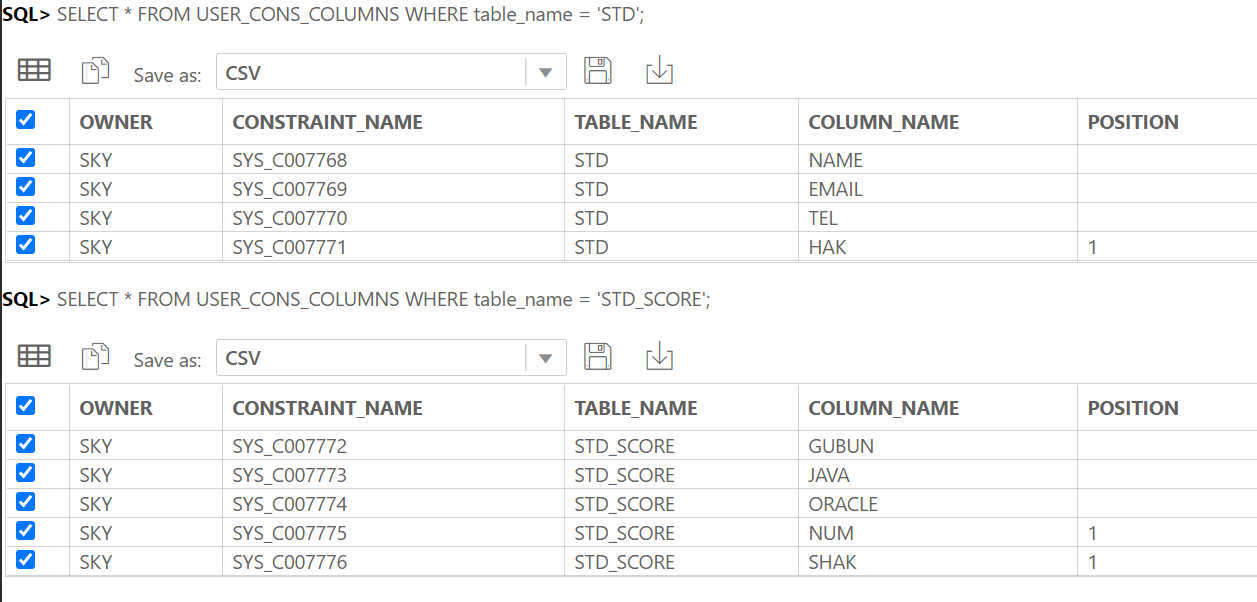
-- 부모 2개 이상으로 기본키를 만든 경우 여러번 출력 됨
SELECT fk.constraint_name, fk.table_name child_table, fc.column_name child_column,
pk.table_name parent_table, pc.column_name parent_column
FROM all_constraints fk, all_constraints pk, all_cons_columns fc, all_cons_columns pc
WHERE fk.r_constraint_name = pk.constraint_name
AND fk.constraint_name = fc.constraint_name
AND pk.constraint_name = pc.constraint_name
AND fk.constraint_type = 'R'
AND pk.constraint_type = 'P'
AND fk.table_name = UPPER('테이블명');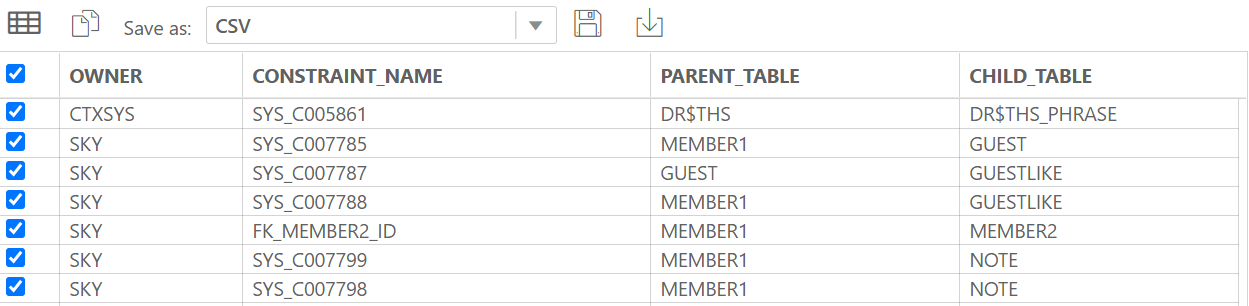

접은 글에 있는 쿼리를 통해 확인 할 수 있다.
테이블 삭제는 테이블 생성한 반대로 삭제하면 된다.
-- 삭제
DROP TABLE note PURGE;
DROP TABLE guestLike PURGE;
DROP TABLE guest PURGE;
DROP TABLE member2 PURGE;
DROP TABLE member1 PURGE;
참조키에 ON DELETE CASCADE 옵션을 넣었을 때
CREATE TABLE test1 (
code VARCHAR2(50) PRIMARY KEY,
subject VARCHAR2(100) NOT NULL
);
CREATE TABLE test2 (
num NUMBER PRIMARY KEY,
code VARCHAR2(50) NOT NULL,
qty NUMBER(10) NOT NULL,
FOREIGN KEY(code)
REFERENCES test1 (code) ON DELETE CASCADE
);
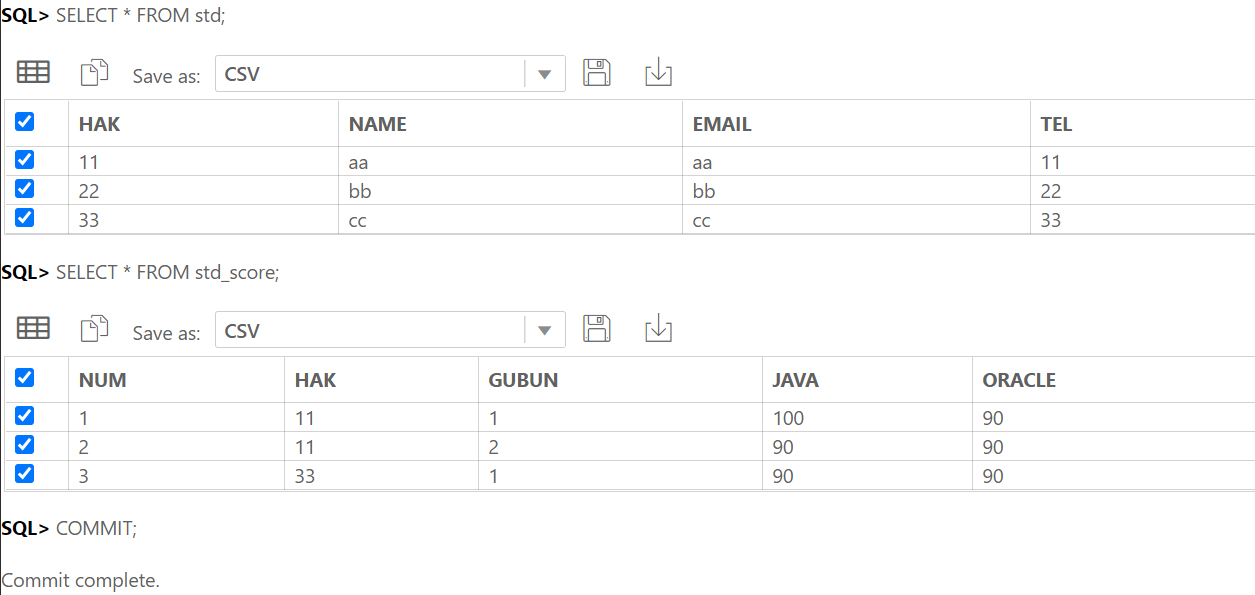
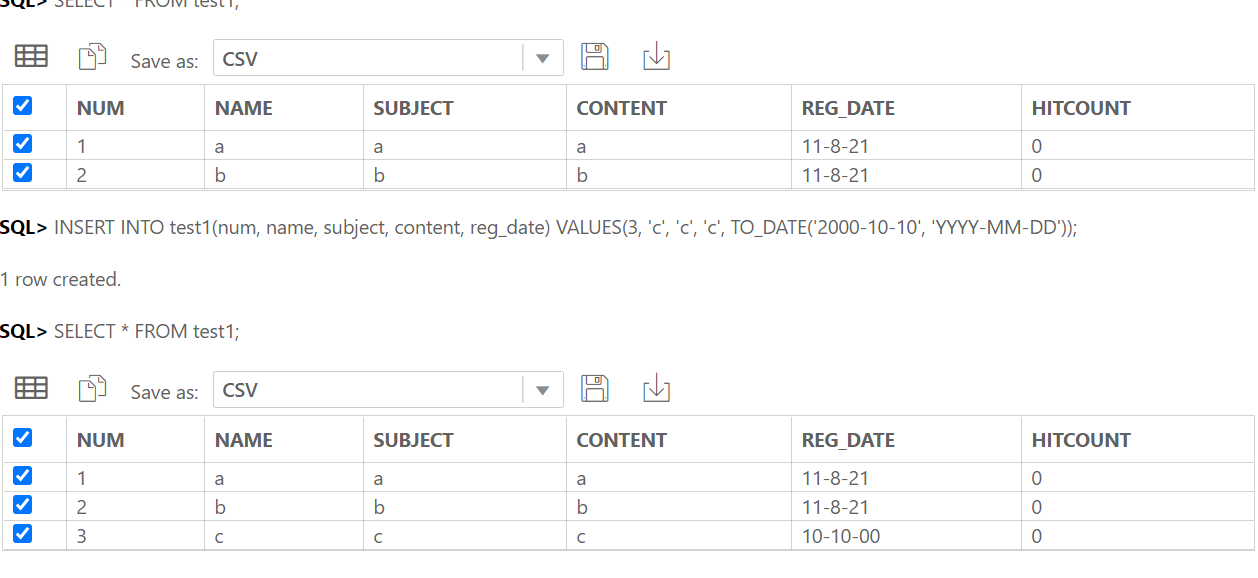
-- 데이터 추가
INSERT INTO test1 (code, subject) VALUES('a', 'a');
INSERT INTO test1 (code, subject) VALUES('b', 'b');
INSERT INTO test1 (code, subject) VALUES('c', 'c');
INSERT INTO test2 (num, code, qty) VALUES (1, 'a', 10);
INSERT INTO test2 (num, code, qty) VALUES (2, 'b', 10);
INSERT INTO test2 (num, code, qty) VALUES (3, 'a', 15);
INSERT INTO test2 (num, code, qty) VALUES (4, 'c', 10);
INSERT INTO test2 (num, code, qty) VALUES (5, 'a', 20);
SELECT * FROM test1;
SELECT * FROM test2;
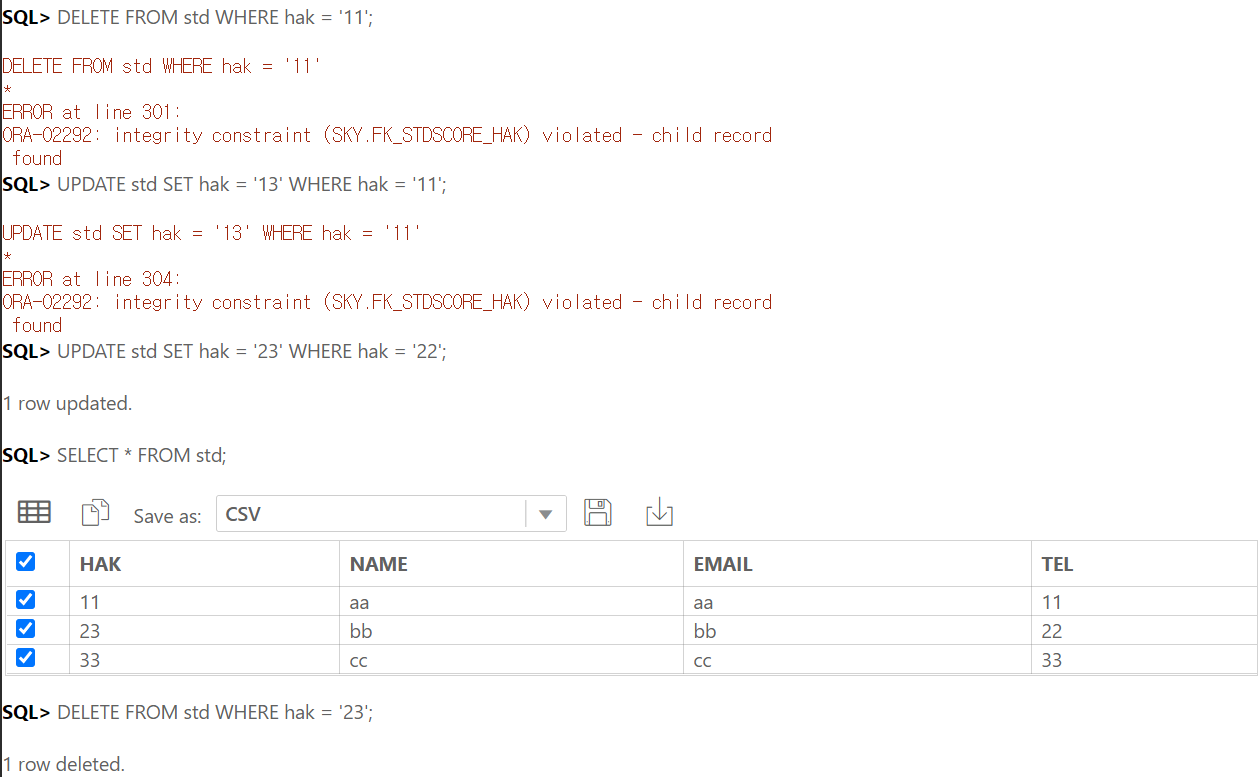
DELETE FROM test1 WHERE code = 'a';
-- ON DELETE CASCADE 옵션으로 test1 테이블과 test2 테이블 모두 삭제됨
SELECT * FROM test1;
SELECT * FROM test2;
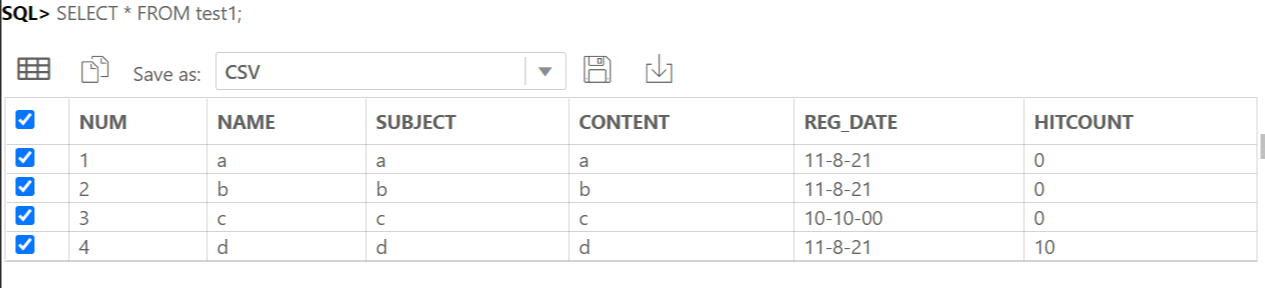
데이터 추가까지 완료한 모습.
ON DELETE CASCADE가 참조키에 있는 경우, 자식 테이블에서 참조하는 값을 부모테이블에서 지우게 되면 해당하는 값을 가진 모든 데이터는 부모, 자식 테이블에서 삭제된다.

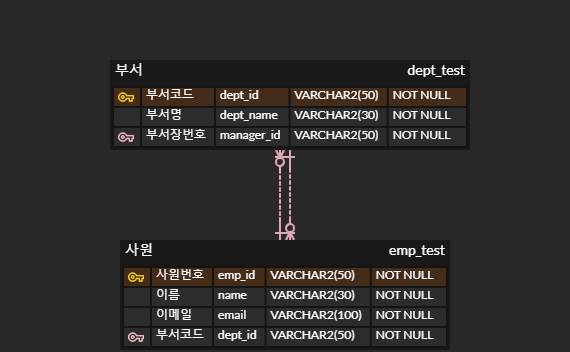
이 ERD에 해당하는 테이블을 만들어보자.
CREATE TABLE dept_test (
dept_id VARCHAR2(30),
dept_name VARCHAR2(50) NOT NULL,
manager_id VARCHAR2(30) NOT NULL,
PRIMARY KEY (dept_id )
);
CREATE TABLE emp_test (
emp_id VARCHAR2(30),
name VARCHAR2(50) NOT NULL,
email VARCHAR2(50) NOT NULL,
dept_id VARCHAR2(30) NOT NULL,
PRIMARY KEY ( emp_id ),
CONSTRAINT fk_empTest_deptId
FOREIGN KEY (dept_id) REFERENCES dept_test ( dept_id)
);
ALTER TABLE dept_test ADD CONSTRAINT fk_deptTest_managerId FOREIGN KEY (manager_id)
REFERENCES emp_test( emp_id );두 테이블이 서로의 컬럼을 참조키로 가지고 있어서 테이블 생성 후 ALTER TABLE로 FOREIGN KEY를 주었다.
이런 테이블을 삭제할 때는
DROP TABLE emp_test CASCADE CONSTRAINTS PURGE;
DROP TABLE dept_test CASCADE CONSTRAINTS PURGE;이렇게 CASCADE CONSTRAINTS 를 넣고 삭제해야한다.
참조키를 비활성화/활성화 시키는 방법을 알아보자.
실습을 위한 예시 생성
CREATE TABLE dept_test (
dept_id VARCHAR2(30) PRIMARY KEY,
dept_name VARCHAR2(50) NOT NULL,
manager_id VARCHAR2(30) NOT NULL
);
CREATE TABLE emp_test (
emp_id VARCHAR2(30) PRIMARY KEY,
name VARCHAR2(50) NOT NULL,
email VARCHAR2(50) NOT NULL,
dept_id VARCHAR2(50) NOT NULL
);
-- 참조키 제약 조건
ALTER TABLE dept_test
ADD CONSTRAINT fk_deptTest_managerId FOREIGN KEY (manager_id) REFERENCES emp_test(emp_id);
ALTER TABLE emp_test
ADD CONSTRAINT fk_empTest_deptId FOREIGN KEY (dept_id) REFERENCES dept_test(dept_id);
SELECT * FROM tab;
-- 데이터 추가
INSERT INTO dept_test(dept_id, dept_name, manager_id) VALUES ('a1', '영업부', '1001');
-- 에러 ORA-02291 : 참조키가 존재하지 않음
INSERT INTO emp_test(emp_id, name, email, dept_id) VALUES ('1001','김영업', 'kim@a.com', 'a1');
-- 에러 ORA-02291 : 참조키가 존재하지 않음서로의 컬럼을 참조키로 가지고 있기 때문에 이 경우에는 다른 테이블의 참조키를 비활성화 하고 데이터를 추가해야한다.
-- 참조키 비활성화 시키기 (삭제는 안하고 잠시 사용하지 못하게 막음)
ALTER TABLE dept_test DISABLE CONSTRAINT fk_deptTest_managerId CASCADE;
ALTER TABLE emp_test DISABLE CONSTRAINT fk_empTest_deptId CASCADE;
-- CASCADE : 부모 테이블과 자식 테이블의 설정이 되어 있을 때
-- 부모 테이블의 제약 조건을 비활성화하면 이를 참조하는 자식 테이블의 제약조건까지 비활성화CASCADE ? 부모 테이블과 자식 테이블 설정이 되어있을 때, 부모 테이블의 제약 조건을 비활성화하면 이를 참조하는 자식 테이블의 제약조건까지 비활성화된다.
비활성화 확인해보자.
-- 비활성화 확인
SELECT * FROM USER_CONSTRAINTS WHERE table_name = UPPER('dept_test');
SELECT * FROM USER_CONSTRAINTS WHERE table_name = UPPER('emp_test');
-- status 컬럼참조키를 비활성화 하면 참조키 제약 조건 위반 데이터를 추가할 수 있다.
INSERT INTO dept_test(dept_id, dept_name, manager_id) VALUES ('a1', '영업부', '1001');
INSERT INTO dept_test(dept_id, dept_name, manager_id) VALUES ('b1', '개발부', '2001');
INSERT INTO dept_test(dept_id, dept_name, manager_id) VALUES ('c1', '총무부', '3001');
SELECT * FROM dept_test;
INSERT INTO emp_test(emp_id, name, email, dept_id) VALUES ('1001','김영업', 'kim@a.com', 'a1');
INSERT INTO emp_test(emp_id, name, email, dept_id) VALUES ('2001','나개발', 'na@a.com', 'b1');
SELECT * FROM emp_test;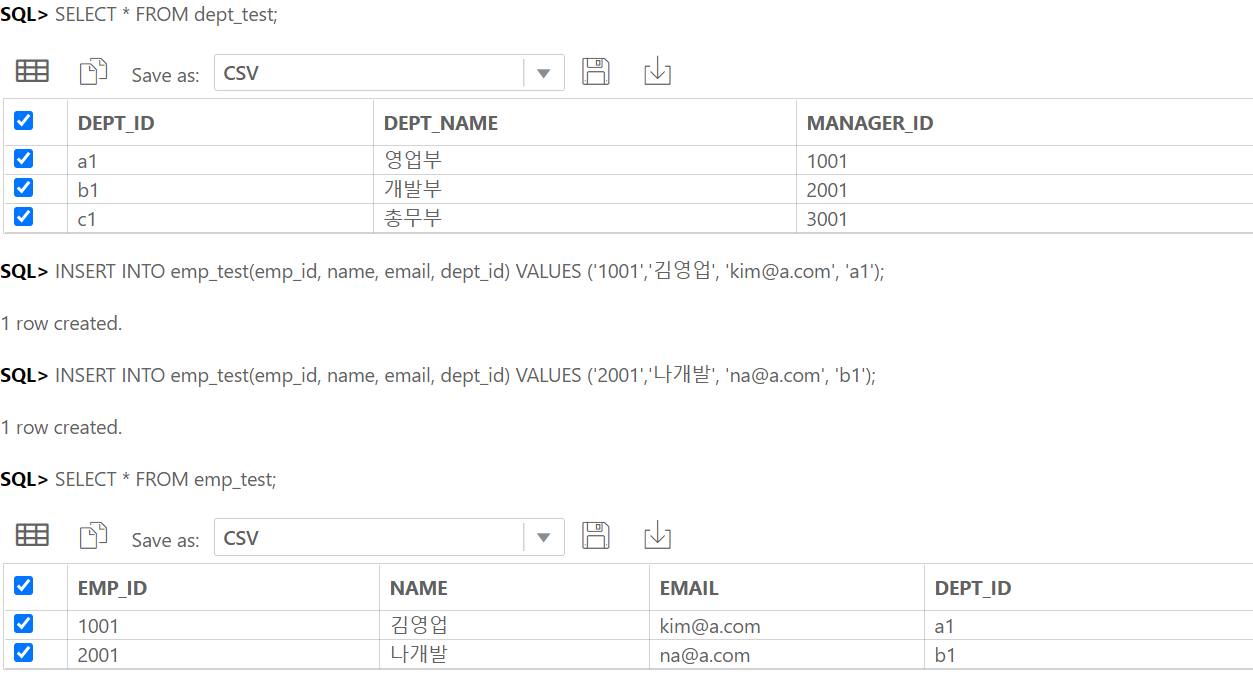
이 후 다시 참조키를 활성화 하면 에러가 발생하는데, 제약조건 위반 데이터가 존재하기 때문이다.

dept_test 테이블에는 manager_id로 3001이 있는데 이는 emp_test의 테이블의 emp_id를 참조하는 키 이기 때문이다. 따라서 emp_test 테이블에 emp_id가 3001인 자료가 있어야한다.
INSERT INTO emp_test(emp_id, name, email, dept_id) VALUES ('3001','홍총무', 'hong@a.com', 'c1');
ALTER TABLE dept_test ENABLE CONSTRAINT fk_deptTest_managerId ;
ALTER TABLE emp_test ENABLE CONSTRAINT fk_empTest_deptId ;
emp_id가 3001인 자료를 추가하고 나서 제약조건을 활성화 시키는 명령어를 입력하자,
잘 시행됨을 볼 수 있다.
'쌍용강북교육센터 > 8월' 카테고리의 다른 글
| 0812_Oracle : JOIN을 활용한 문제풀이 [210813 수정] (2) | 2021.08.12 |
|---|---|
| 0812_Oracle : 데이터 사전 확인 (0) | 2021.08.12 |
| 0811_Oracle : 참조키(외래키, FOREIGN KEY) (3) | 2021.08.11 |
| 0811_Oracle : DEFAULT와 CHECK 제약조건 (1) | 2021.08.11 |
| 0811_Oracle : UNIQUE 제약조건과 NOT NULL 제약조건 (1) | 2021.08.11 |