시퀀스 (SEQUENCE) ?
유일한 정수값을 연속적으로 생성하는 객체이다.
시퀀스 번호는 트랜잭션 커밋 또는 롤백과 상관없이 증가한다.
-- 시퀀스 만들기
-- 1부터 1씩 증가하는 시퀀스 작성
CREATE SEQUENCE test_seq1
INCREMENT BY 1
START WITH 1
NOMAXVALUE
NOCYCLE
NOCACHE;-- 시퀀스 목록 확인
SELECT * FROM user_sequences;
SELECT * FROM seq;※ 시퀀스를 만들 때 seq로 시퀀스 명을 부여하면 안된다. seq로 시퀀스 이름을 부여하면 목록을 확인할 때 seq로 시퀀스 확인이 불가하다.

-- 다음 시퀀스 값 가져오기
SELECT test_seq1.NEXTVAL FROM dual;
-- 현재 시퀀스 값 확인
SELECT test_seq1.CURRVAL FROM dual;
※ 동일한 SELECT, INSERT 문에서는 NEXTVAL을 여러번 해도 동일한 값이 나옴에 주의하자.
SELECT test_seq1.NEXTVAL, test_seq1.CURRVAL, test_seq1.NEXTVAL FROM dual;
-- 시퀀스 삭제
DROP SEQUENCE 시퀀스이름;
DROP SEQUENCE test_seq1;
SELECT * FROM seq; -- 확인
-- 1부터 증가하는 시퀀스(기본 캐시 20개)를 만들어보자
CREATE SEQUENCE test_seq1;
SELECT * FROM seq;
CREATE SEQUENCE 시퀀스명; 으로 시퀀스를 생성하면 1부터 증가하는 시퀀스(기본캐시20개)를 자동으로 만들어준다.
기본 캐시가 20개라는 의미는 미리 20개의 시퀀스를 만들어 놓는다는 의미로, 만약 현재 시퀀스가 3인 상태에서 오라클 서버가 재실행되면 다음 시퀀스의 값은 21이 된다.
예제를 통해 시퀀스 만드는 방법을 좀 더 알아보자 >>
-- 100~200까지 100부터 2씩 증가하는 시퀀스(캐시5개, 200 넘어가면 오류)
CREATE SEQUENCE test_seq2
INCREMENT BY 2
START WITH 100
MINVALUE 100
MAXVALUE 200
CACHE 5;-- 10~20까지 3씩 증가하는 시퀀스(캐시3개 최소1, 최대값에 도달하면 처음부터 다시)
CREATE SEQUENCE test_seq3
INCREMENT BY 3
START WITH 10
MINVALUE 1
MAXVALUE 20
CYCLE
CACHE 3;몇 번 실행해서 어떻게 진행되는지 확인해보자
SELECT test_seq1.NEXTVAL, test_seq2.NEXTVAL, test_seq3.NEXTVAL
FROM dual;

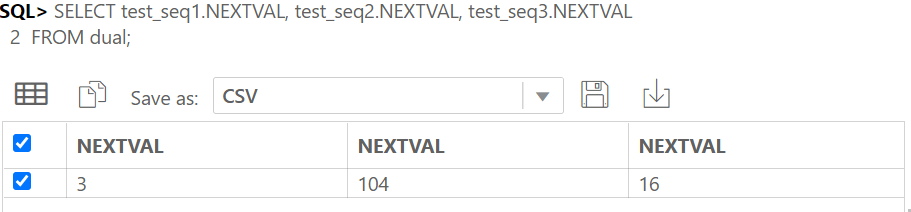


test_seq3의 경우 CYCLE이 설정되어있는데, CYCLE옵션이 있는 경우 명시적으로 CACHE를 지정하거나 NOCACHE로 설정해야한다.
MINVALUE가 1이기 때문에 20을 초과하면 1부터 다시 CYCLE을 만들며 시작된다.
-- 시퀀스 삭제
DROP SEQUENCE test_seq1;
DROP SEQUENCE test_seq2;
DROP SEQUENCE test_seq3;'쌍용강북교육센터 > 8월' 카테고리의 다른 글
| 0818_Oracle : 정규식 (0) | 2021.08.19 |
|---|---|
| 0817_Oracle : SYNONYM 시노님 (2) | 2021.08.18 |
| 0817_Oracle : VIEW 뷰를 이용한 데이터 추가 및 수정 삭제 (0) | 2021.08.18 |
| 0817_Oracle : VIEW 뷰 만들기, 수정하기, 삭제하기 (2) | 2021.08.17 |
| 0817_Oracle : 테이블 변경 (0) | 2021.08.17 |


























