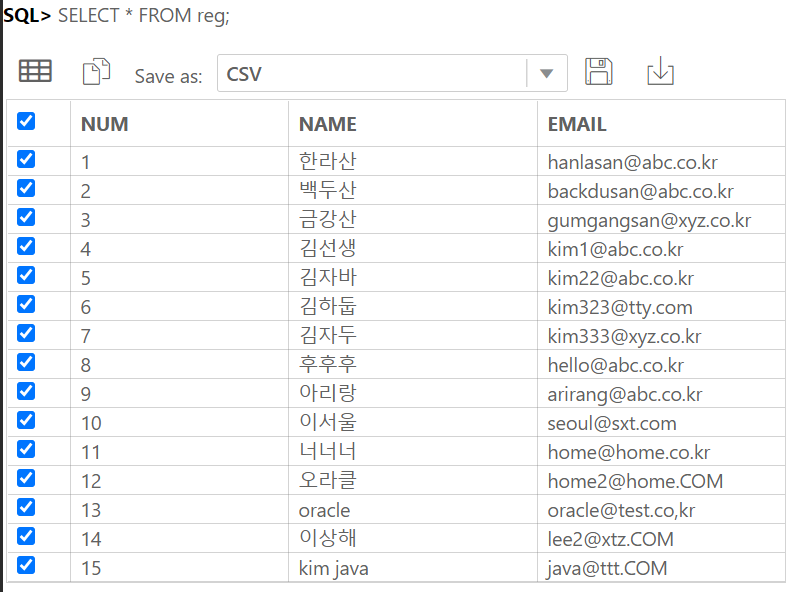
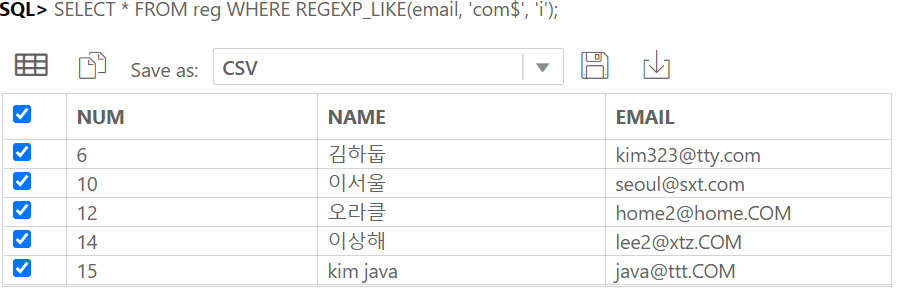
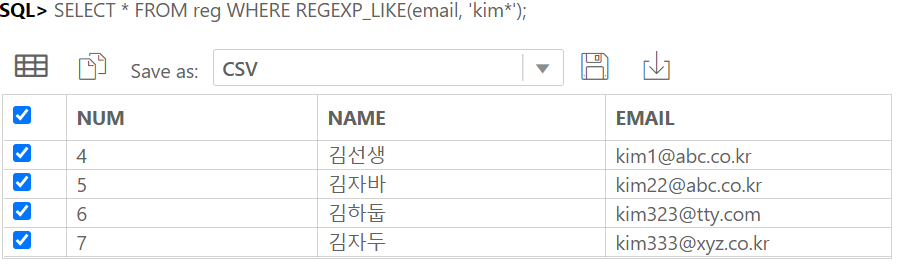
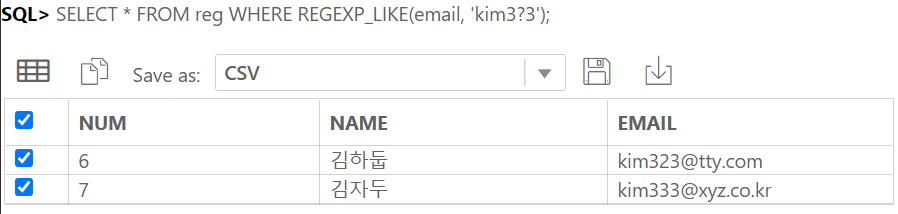
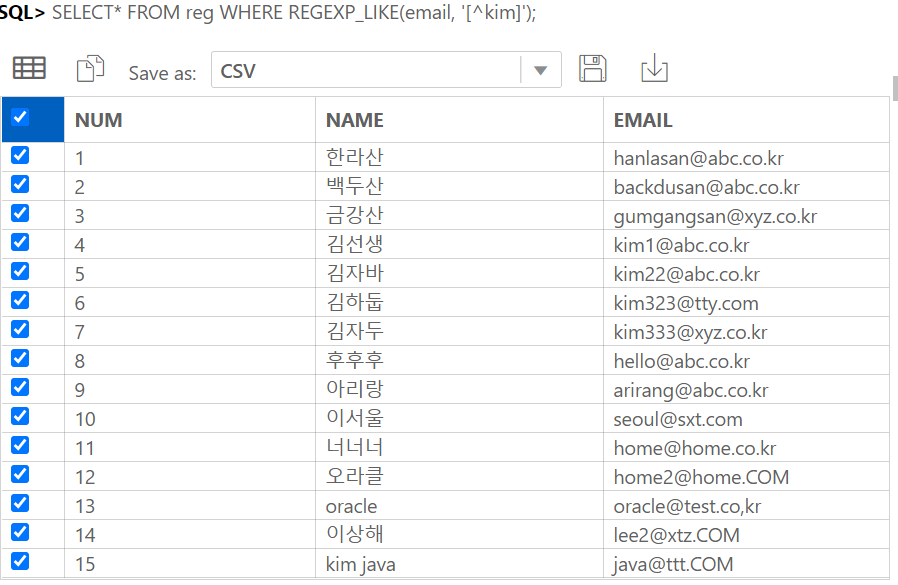
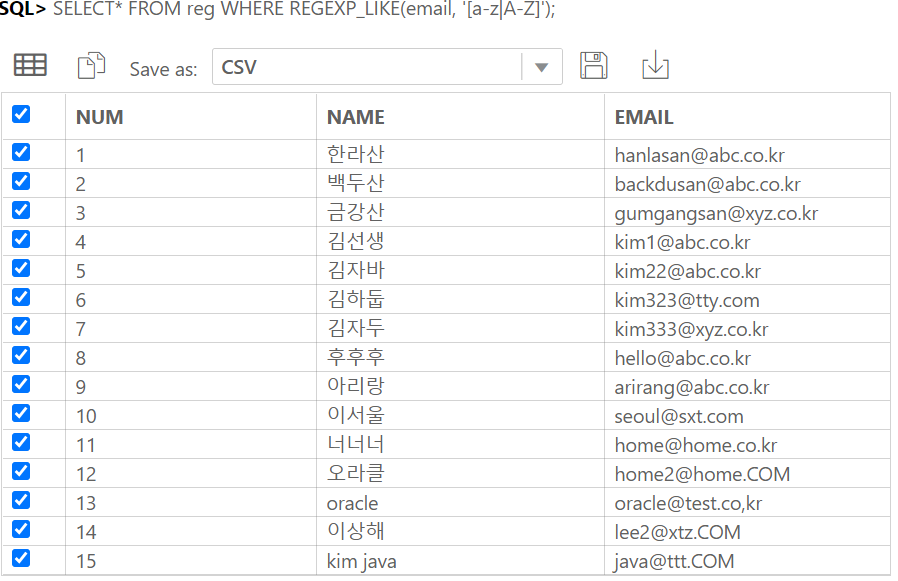
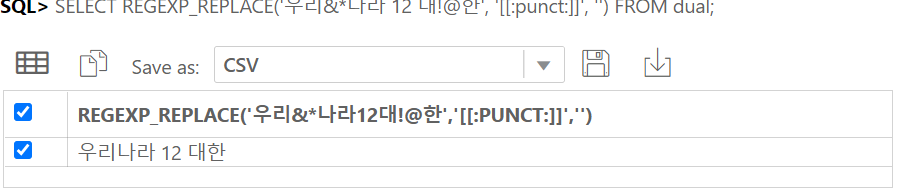
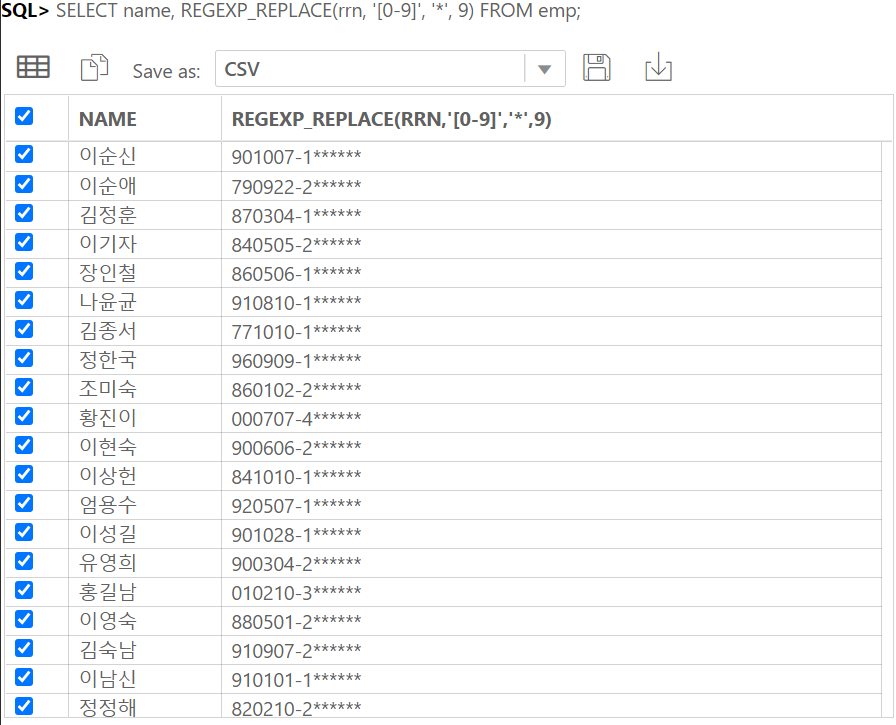
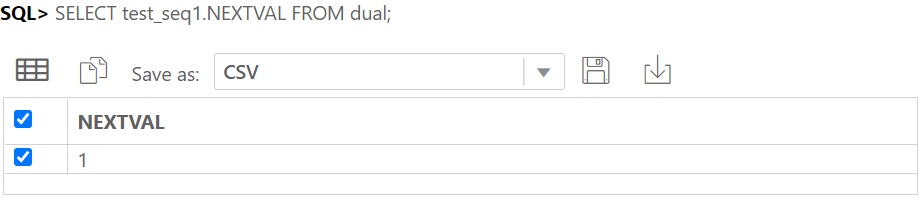
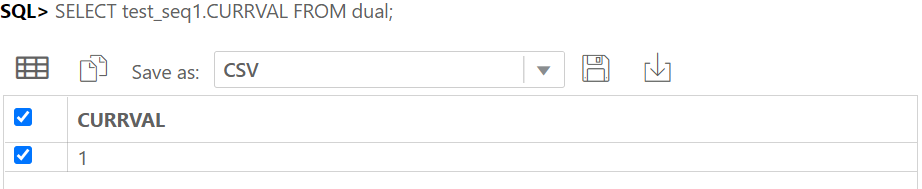
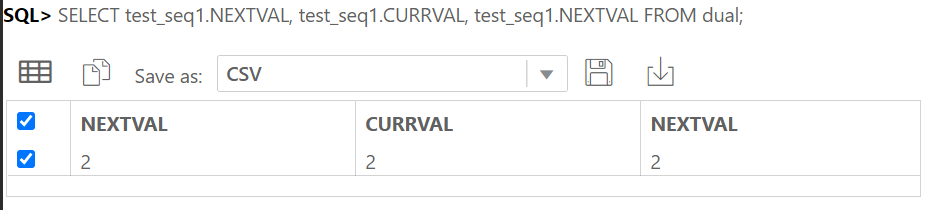
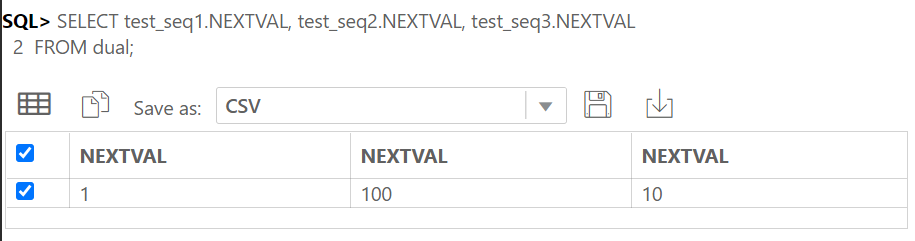
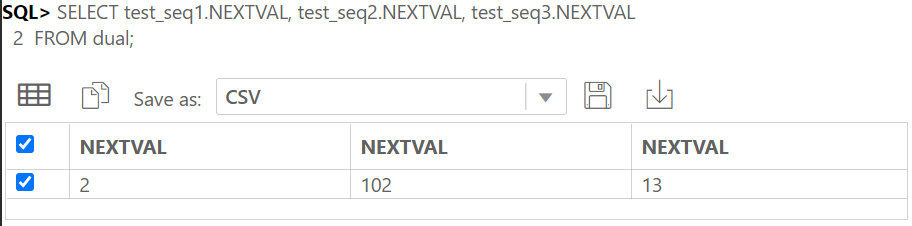
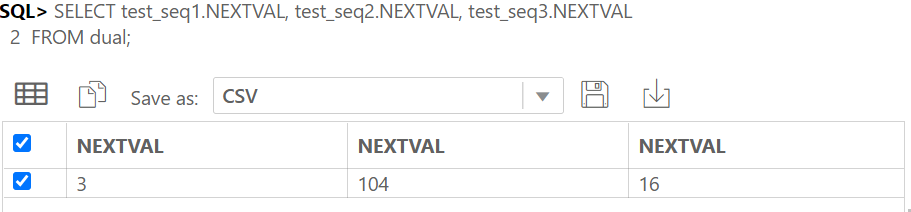
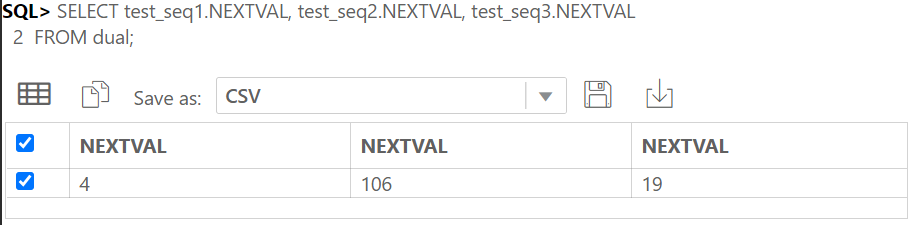
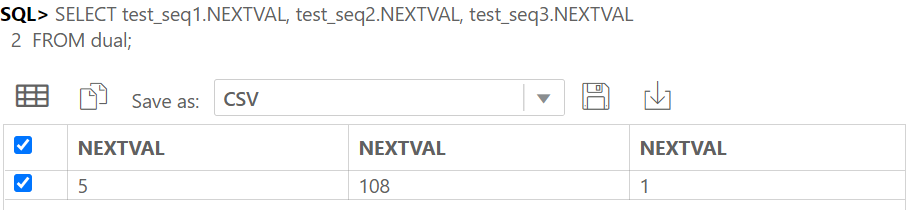
IDENTITY COLUMN 이란 ANSI SQL서 지원하는 자동으로 숫자가 되는 컬럼이다.
오라클에서는 내부적으로 시퀀스를 사용한다.
실습용 테이블 생성
CREATE TABLE test(
num NUMBER GENERATED AS IDENTITY PRIMARY KEY,
subject VARCHAR2(1000) NOT NULL
);생성시 GENERATED BY IDENTITY 를 넣으면 된다.
-- 데이터 추가
INSERT INTO test(subject) VALUES ('a');
INSERT INTO test(subject) VALUES ('b');
INSERT INTO test(subject) VALUES ('c');
SELECT * FROM test;

자동으로 num 에 숫자가 들어가 있는 것을 확인할 수 있다.
INSERT INTO test(num, subject) VALUES (10, 'x');기본적으로 ALWAYS 옵션이므로 INSERT, UPDATE에서 값을 수정할 수 없다.
그러므로 num의 현재 값을 알기위해서
SELECT* FROM user_objects;에서 ISEQ$$ 으로 시작하는 SEQUENCE를 찾으면된다.
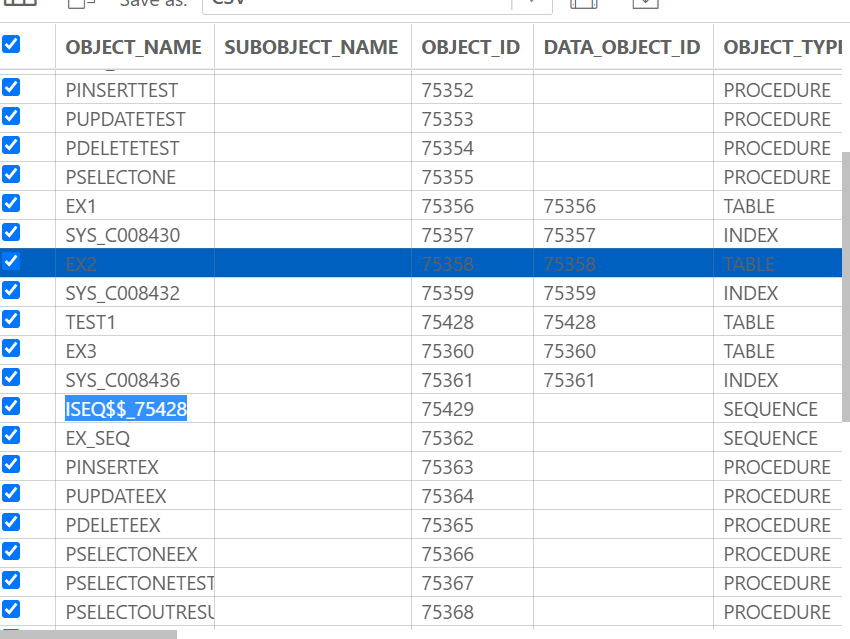
SELECT ISEQ$$_75428.CURRVAL FROM dual;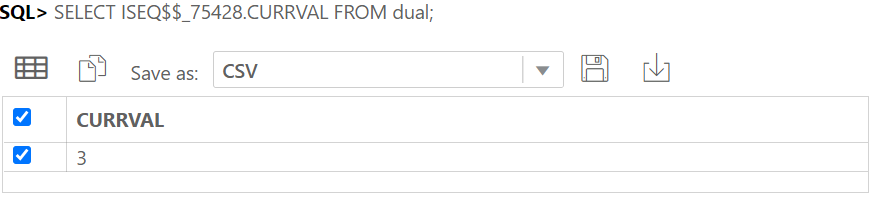
BY DEFAULT ON NULL : 특정 값으로 IDENTITY 컬럼 값을 지정할 수 있다.
NULL 이면 IDENTITY 값으로 추가하는 테이블을 만들어보자.
CREATE TABLE test(
num NUMBER GENERATED BY DEFAULT ON NULL AS IDENTITY,
subject VARCHAR2(1000) NOT NULL
);INSERT INTO test(subject) VALUES ('a'); -- 1 a 추가
INSERT INTO test(num, subject) VALUES (9, 'b'); -- 9 b 추가
INSERT INTO test(num, subject) VALUES (null, 'c'); -- 2 c 추가
INSERT INTO test(subject) VALUES ('d'); -- 3 d 추가-- BY DEFAULT 옵션 제거
ALTER TABLE test MODIFY (num GENERATED ALWAYS AS IDENTITY);ALWAYS는 INSERT, UPDATE에서 IDENTITY 컬럼 수정이 불가능하다.
IDENTITY 컬럼은 테이블을 만들때만 지정할 수 있고, 테이블이 만들어진 후 일반컬럼을 IDENTITY 컬럼으로는 변경이 불가능하다. 단, IDENTITY 컬럼을 만든 후 속성을 변경할 수 있다.
BY DEFAULT 옵션을 제거했기 때문에
INSERT INTO test(num, subject) VALUES (99, 'y'); -- 에러자동으로 생성되는 IDENTITY 컬럼에 값을 넣으면 오류이다.
-- 존재하는 테이블에 IDENTITY 컬럼 추가
CREATE TABLE test(
qty NUMBER NOT NULL,
subject VARCHAR2(1000) NOT NULL
);
ALTER TABLE test ADD( num NUMBER GENERATED AS IDENTITY PRIMARY KEY);IDENTITY 컬럼을 존재하는 테이블에 추가하면된다.
'쌍용강북교육센터 > 8월' 카테고리의 다른 글
| 0820_Oracle : INDEX (0) | 2021.08.23 |
|---|---|
| 0819_Oracle[PL/SQL] : PROCEDURE, FUNCTION 예제 (2) | 2021.08.20 |
| 0818_Oracle : INVISIBLE, VISIBLE COLUMN (1) | 2021.08.19 |
| 0818_Oracle : 페이징처리 [21.08.23 수정] (2) | 2021.08.19 |
| 0818_Oracle : 정규식 (0) | 2021.08.19 |